Agentless: Demystifying LLM-based Software Engineering Agents
August 24, 2024 | 870 words | 5min read
Paper Title: Agentless: Demystifying LLM-based Software Engineering Agents
Link to Paper: https://arxiv.org/abs/2407.01489
Date: 1. July 2024
Paper Type: LLM, Code-generation
Short Abstract:
Recently, there have been made many advancements in the field of autonomous software development using large language models (LLMs). Most of this progress has been driven by agents. These agents are equipped with tools that allow them to run commands, observe the codebase, and plan future actions. However, these agents come with significant complexity. This paper poses the question: Do we really need all this complexity?
Agentless is an approach to solving software development tasks without the use of agents. It operates in a two-phase process: identifying the buggy code and then repairing it. Agentless is cost-effective to execute and achieves a high score of 27% on SWE-Bench.
1. Introduction
For quite some time, LLMs have been the default choice for code generation, with models like GPT-4 and Claude-3.5 demonstrating high proficiency in generating code snippets. However, applying them at the codebase level for software projects—specifically to fix issues and develop new features—has not been extensively studied until recently, with the introduction of the SWE-Bench dataset. SWE-Bench is a dataset that consists of GitHub issues from popular python projects and the corresponding git patches from the pull requests that fixed those issues.
Most approaches for SWE-Bench, such as SWE-Agent, Devin, or AutoCodeRover, have used an agent-based approach. In this context, an agent is an LLM equipped with a set of tools that allow it to iteratively interact with a project’s codebase. These interactions include opening and reading files, editing files, navigating the codebase, and observing feedback. The agent makes multiple attempts, with each attempt consisting of several actions, each one depending on the feedback from the previous action.
There are several problems with the agent-based approach:
- Complex and difficult-to-use tools and APIs: Tool usage often requires the LLM-generated response to follow an exact format, which can be challenging for an LLM to achieve consistently.
- Lack of control in planning: In an agent-based approach, the agent autonomously decides the next action based on the feedback from the previous one. However, due to the large action space, it can be easy for the LLM to become confused.
- Limited ability to self-reflect: LLMs often struggle to differentiate between useful feedback and misleading information, which can lead them down the wrong path.
Agentless seeks to address these issues by eliminating the agent concept altogether. Instead, Agentless uses two simple phases: localization and repair. Localization works in a hierarchical manner, first identifying relevant files, then classes, and finally methods. For the repair phase, Agentless creates multiple candidates for software patches, checks them for syntax errors, and tests them against the existing test suite. Afterward, it ranks the patches and selects the best solution.
2. Agentless
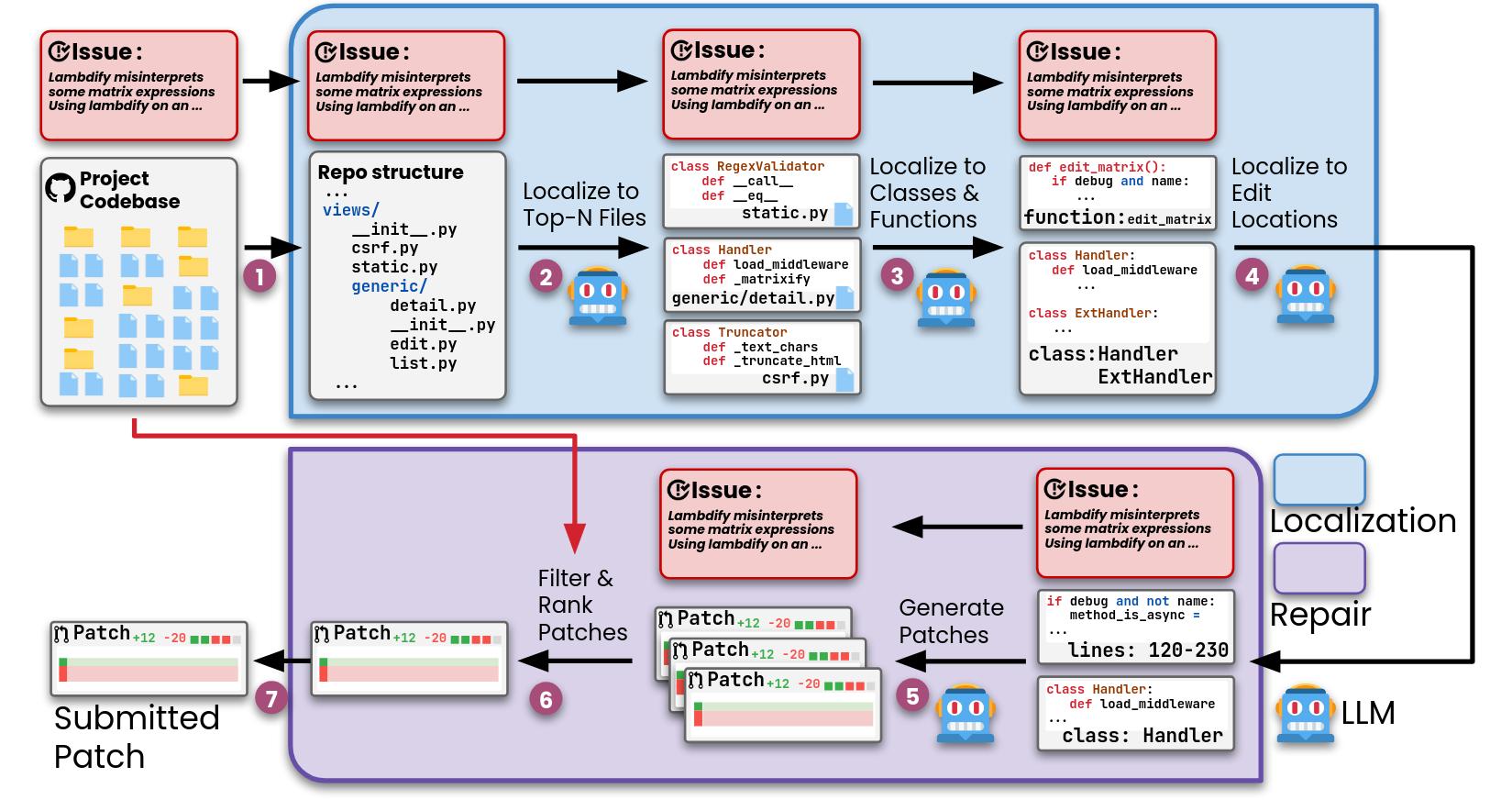
Agentless works in the following steps:
- The existing project codebase and issue description are taken as input.
- The codebase is transformed into a tree-like structure.
- The LLM is asked to rank the top N most suspicious files that need editing to solve the issue.
- For each selected file, the LLM is provided with a list of class and function declarations and is asked to output a list of suspicious classes.
- The full code for these suspicious classes and functions is then provided to the LLM.
- The LLM is asked to edit these locations to fix the issue based on the full code snippets.
- The generated software patch is filtered for syntax errors and test failures.
- The generated patches are ranked by the LLM, and the top one is selected as the solution.
2.1 Localization
The codebase is structured as a tree:
“It begins with the root folder of the repository and organizes code files or folder names. Files and folders at the same directory level are aligned vertically, and files/folders in sub-directories are indented.”
This structure is then passed to the LLM as input for step (1).
To find suspicious classes, the LLM is provided with a skeleton of the chosen files: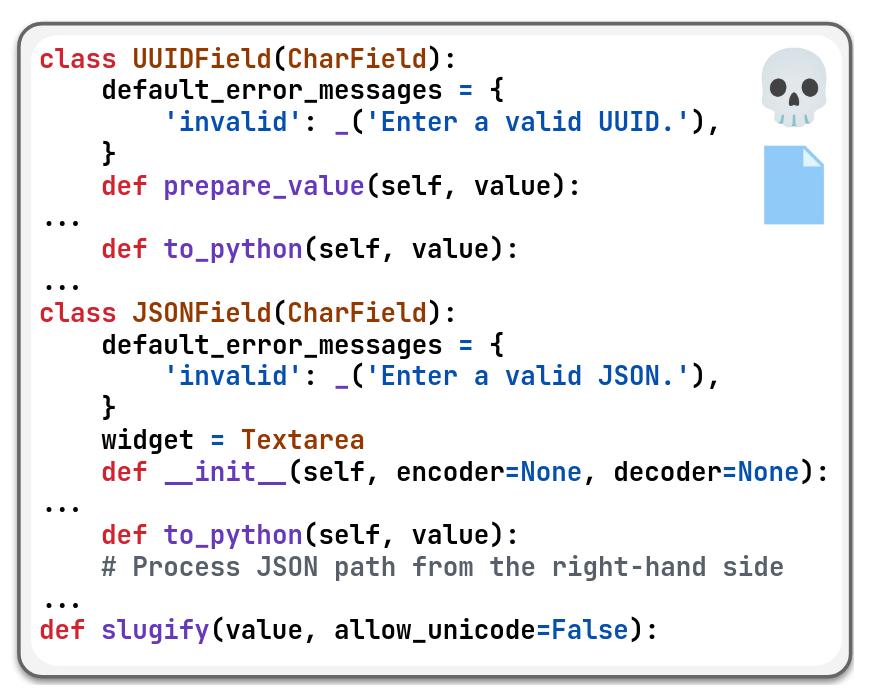
Finally, the full source code of these selected classes is given to the LLM. The LLM is then asked to identify a set of edit locations, specified by line numbers, functions, or classes.
2.2 Repair
First, a context window for the identified edit locations is built. This involves using the identified line numbers and adding a few additional lines (controlled by a parameter). The LLM is then asked to create a search/replace edit in the form of a simple git diff.
Multiple patches are generated by the LLM. Patches with invalid syntax or failing tests are removed. For the remaining patches, Agentless uses majority voting: the patch with the highest number of occurrences is selected.
3. Experiments
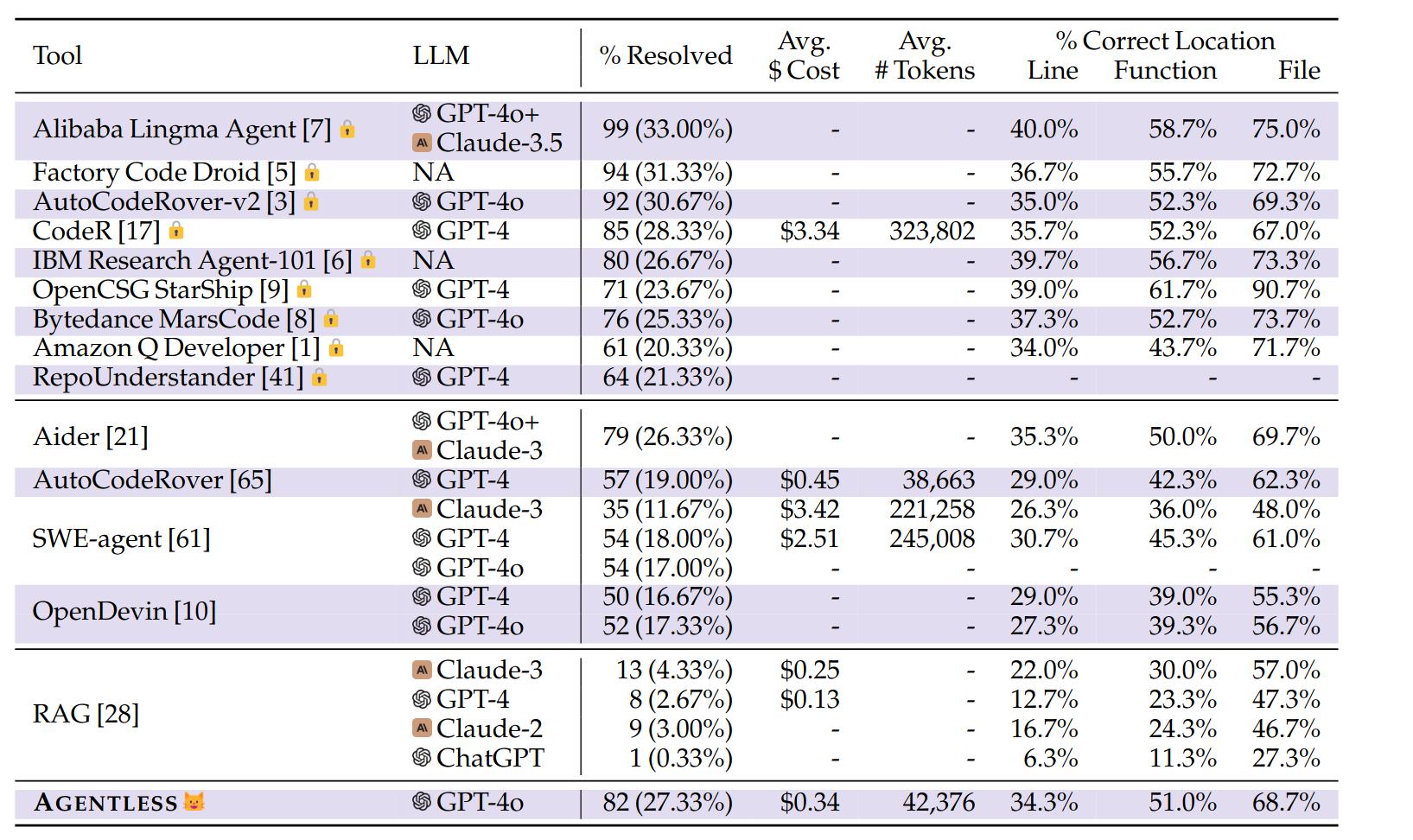
Agentless was able to solve 82 out of 300 problems (27.33%). While there are techniques that achieve better results, they rely on agents and are more complicated.
4. Conclusion
Agentless is an intriguing approach that explores a unique direction. Instead of focusing on agents, it simplifies the process, which results in competitive performance on the SWE benchmark.
 reply via email
reply via email