Automatic Test Pattern Generation and Compaction for Deep Neural Networks
April 20, 2026 | 1,226 words | 6min read
Paper Title: Automatic Test Pattern Generation and Compaction for Deep Neural Networks
Link to Paper: https://dl.acm.org/doi/10.1145/3566097.3567912
Date: 31. Jan 2023
Paper Type: Machine Learning, Software Defect Analysis, Deep Neural Networks, Convolutional Neural Networks, Testing
Short Abstract: Deep Neural Networks (DNNs) have become very popular in a wide array of fields due to their strong performance. Therefore, detecting faults is very important when applying DNNs in real-world scenarios. This paper proposes an automatic test pattern generation method to detect faults in DNNs.
1. Introduction
Deep Neural Networks (DNNs) are widely used in critical applications such as self-driving cars, healthcare, and fraud detection, making their reliability essential. However, defects during manufacturing or runtime faults can degrade performance or cause rare but serious misclassifications, even if overall accuracy appears unaffected.
Testing DNNs is challenging because, unlike traditional systems, their behavior is learned from data rather than explicitly defined. As a result, standard functional testing is less effective, and training/validation datasets may not cover all real-world scenarios.
To address this, the paper proposes an Automatic Test Pattern Generation (ATPG) method to detect functional faults (e.g., stuck-at faults in neurons or filters). It generates input patterns that expose incorrect outputs when faults occur. To reduce testing overhead, the approach also uses heuristics and K-means clustering to minimize the number of test patterns while maintaining full fault coverage.
2. Preliminaries
2.1 Neural Network
A neuron with input \( x \), weights \( w \), and bias \( b \) is computed as:
$$ y = \phi(xw + b) $$where \( \phi \) is a nonlinear activation function.
Neural networks are often used for classification tasks. In this context, the Softmax function can be used in the last layer to obtain a probability distribution over classes:
$$ \text{Softmax}(x_i) := \frac{\exp(x_i)}{\sum_k \exp(x_k)} $$2.2 Related Work
In previous work, test patterns have been generated by adding small perturbations to training inputs. For example, in image classification systems, small amounts of noise can be added to an input image to fool the network—these are called adversarial examples.
One common method to generate such examples is the Fast Gradient Sign Method (FGSM):
$$ \eta = \epsilon \cdot \text{sign}(\nabla_x L_\theta(x, y)) $$where \( \nabla_x L_\theta(x, y) \) is the gradient of the loss function with respect to the input \( x \) for the example \( (x, y) \). Adversarial examples are then generated as:
$$ x + \eta $$However, this approach has several limitations:
- Adversarial methods depend heavily on a specific input \( x \) and its label \( y \), making them less flexible.
- They introduce only very small perturbations to remain imperceptible, which limits their effectiveness as test patterns.
- The generated inputs remain very close to the original data, reducing their usefulness and making them harder to compress or optimize.
- Standard compression techniques can remove the subtle perturbations that make them effective.
- Prior work has mainly focused on faults in network weights, while largely neglecting faults at the neuron level.
3. Methodology
3.1 Fault Modeling
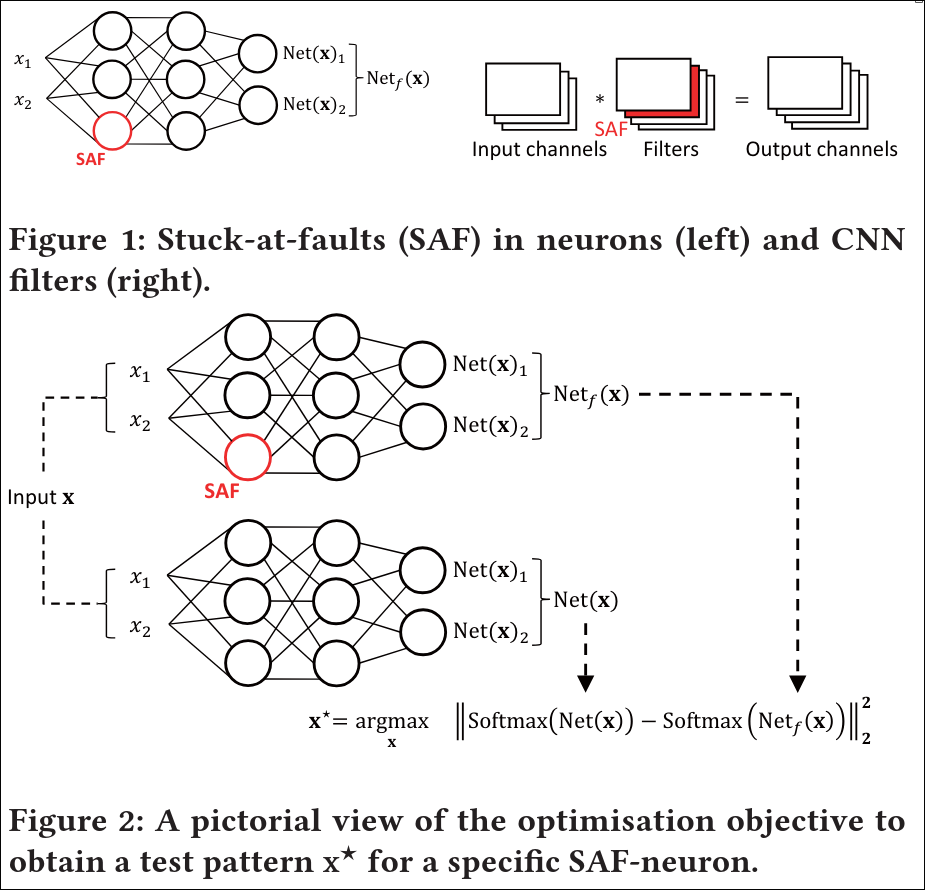
Stuck-at faults (SAFs) are a common fault model in digital circuits, where a signal is fixed at a constant value. This idea is adapted here for neural networks.
Instead of modeling faults inside individual components (such as weights, MAC operations, or activation functions), the paper simplifies the approach by placing the fault at the neuron’s output. The reasoning is that internal faults only matter if they affect the neuron’s final output.
A neuron is considered faulty if it always outputs a constant value \( v \), regardless of the input—that is, it is “stuck” at that value.
The choice of \( v \) depends on the activation function. Typical values include:
- Extreme values (e.g., −1 or 1 for tanh), representing abnormal firing
- Middle values (e.g., 0), which can also indicate faults
The same concept applies to convolutional filters in CNNs, where an entire output channel can be treated as “stuck” at a constant value.
3.2 Test Pattern Generation
Testing assumption: Internal faults cannot be directly inspected. Instead, we:
- Feed an input \( x \) into the network
- Observe the output \( \text{Net}(x) \)
A fault is detected if the predicted class (i.e., the maximum output) differs between the fault-free and faulty networks.
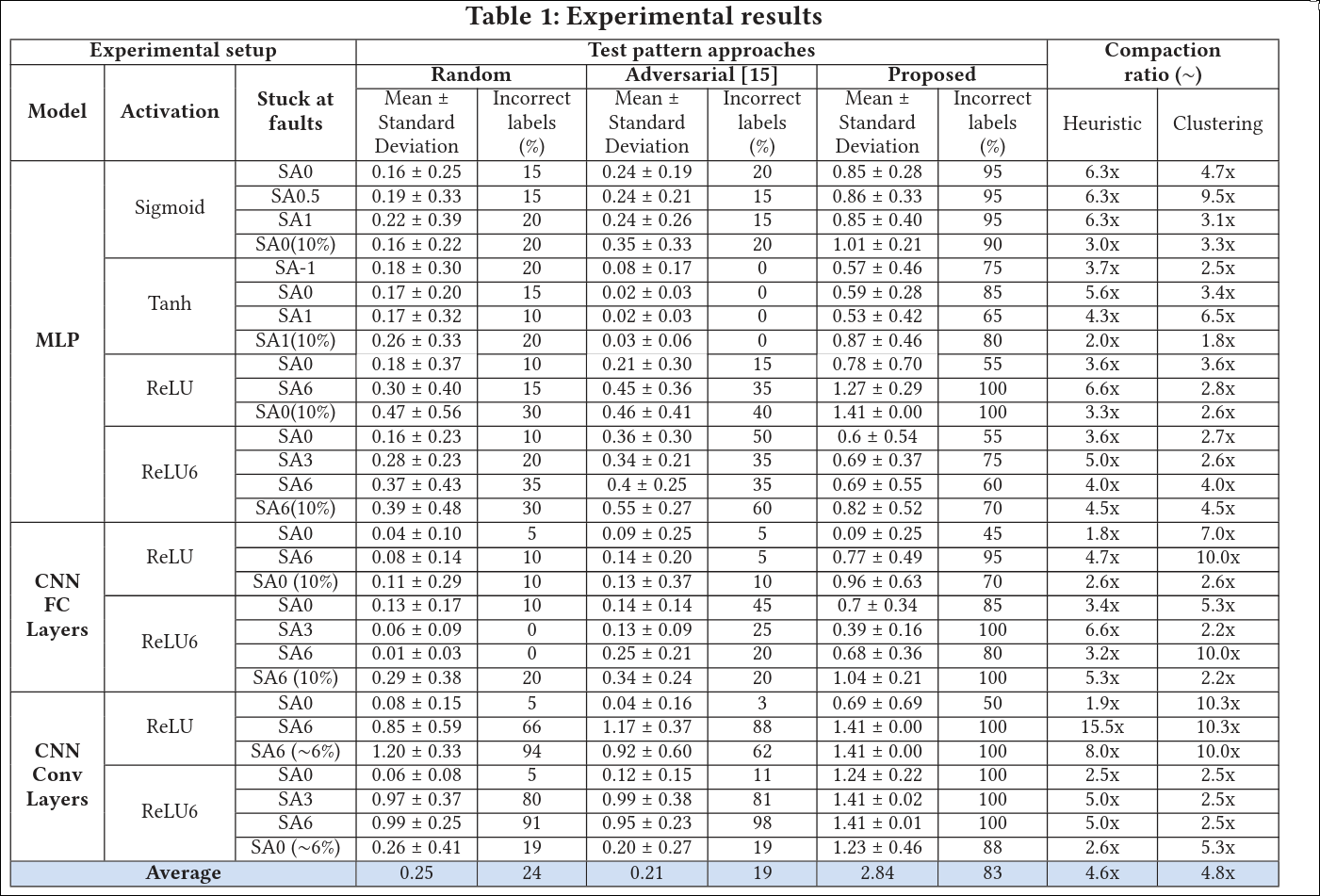
Core idea: Generate inputs that maximize the difference between the outputs of the correct network \( \text{Net}(x) \) and the faulty network \( \text{Net}_f(x) \).
Why Softmax matters: Outputs are compared after applying Softmax because:
- It converts outputs into probabilities
- The probabilities are interdependent (they sum to 1)
Thus, increasing one class probability decreases others, making class changes more likely.
Optimization objective: Find an input \( x^* \) that maximizes the difference between the two output distributions, measured using the squared Euclidean distance:
$$ x^{*} = \arg\max_{x \in X} \left| \text{Softmax}(\text{Net}(x)) - \text{Softmax}(\text{Net}_f(x)) \right|_2^2 $$How the input is found:
- Formulate the problem as an optimization task
- Use gradient-based methods (e.g., gradient descent or Adam)
- Iteratively adjust the input to increase the difference
- Ensure inputs remain valid (e.g., clip pixel values to a valid range)
Initialization and stopping:
- Start from random inputs or training samples
- Stop when improvements plateau or after a fixed number of steps
- Optionally restart multiple times for better results
Key advantage over adversarial examples: Generated test inputs do not need to resemble real data or remain close to existing samples. This provides greater flexibility and makes them more effective for:
- Fault detection
- Test pattern compression and efficiencay
During Inference After generating the test pattern \(x*\), the tester also stores the expected response:
$$ y*=Net(x*) $$So the test actually consists of a pair: \((x*,y*)\), where: \(x*\) = test input and \(y*\) = expected output of a healthy network. So during inference a healthy network will produce the ouput \(Net(x*) \approx y*\) and a unheatlhy network will produce \(Net(x*) \neq y*\).
3.3 Test Pattern Compression
In large neural networks, the number of possible faults can be very high (e.g., multiple fault values per neuron), making exhaustive testing impractical. Therefore, the number of test patterns must be reduced.
The paper proposes two approaches:
- K-means clustering: Group similar test patterns and select representative candidates from each cluster
- Greedy set cover: Rank test patterns by how many faults they detect, then iteratively select the ones that cover the most remaining faults
4. Experiments
4.1 Setup
The authors tested different neural network architectures, including both fully connected networks and CNNs. The learning rate was determined using grid search. The datasets used were MNIST and CIFAR-10. Training was performed with a batch size of 32 for 10 epochs.
4.2 Results
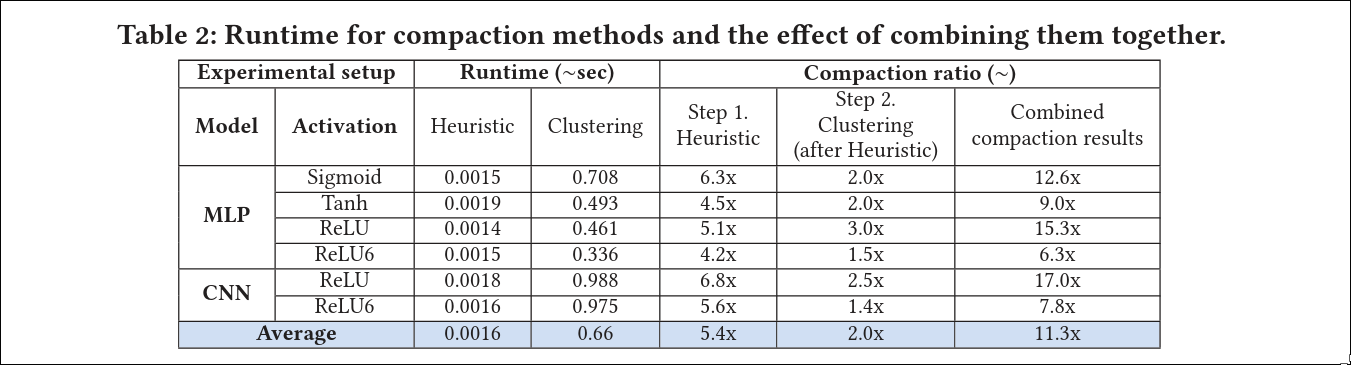
Compared to other test pattern generation methods, the proposed approach performs well, particularly in terms of the number of detected faults.
5. Conclusion
The method appears to be effective in detecting faults in DNNs while keeping the number of required test patterns manageable.
Thoughts
- What is one limitation or open question? (Gap)
- The stuck-neuron fault model may be unrealistic.
- Is this approach scalable?
- Does this work with different architectures?
- The evaluation metric may be poor:
- A fault might change the confidence without changing the top class.
- Alternatives such as KL divergence could be explored.
- Latent-space-based metrics could also be considered.
- Not all faults are equally important. For safety-critical systems, can we prioritize more critical faults?
- Does this approach generalize to other domains such as NLP, speech, reinforcement learning, or multimodal systems?
- How does fault generation interact with robustness techniques such as dropout?
 reply via email
reply via email