Byte Latent Transformer: Patches Scale Better Than Tokens
December 23, 2024 | 566 words | 3min read
Paper Title: Byte Latent Transformer: Patches Scale Better Than Tokens
Link to Paper: https://ai.meta.com/research/publications/byte-latent-transformer-patches-scale-better-than-tokens/
Date: 12. December 2024
Paper Type: LLM, Alignment, Tokenization
Short Abstract:
Byte Latent Transformer (BLT) is a new byte-level LLM architecture that matches the performance of tokenization-based LLMs while being significantly more robust during inference.
BLT utilizes dynamically sized patches instead of tokens, determined by the entropy of the next byte.
1. Introduction
Tokenization has traditionally been essential in training large language models (LLMs) because training an LLM directly on bytes is computationally expensive. Improvements in attention mechanisms offer limited benefits in large models since the computational cost is dominated by operations on every byte.
The authors propose dynamically grouping bytes into patches. Unlike traditional methods, BLT (Byte Latent Transformer) has no fixed vocabulary. Instead, arbitrary groups of bytes are mapped to patch representations using encoder-decoder modules.
This approach is more efficient than tokenization, as traditional LLMs allocate the same amount of resources to every token. In contrast, BLT allows the model to “decide” how much computation to allocate. For instance, predicting the end of a sentence requires less computation than predicting the start of a sentence.
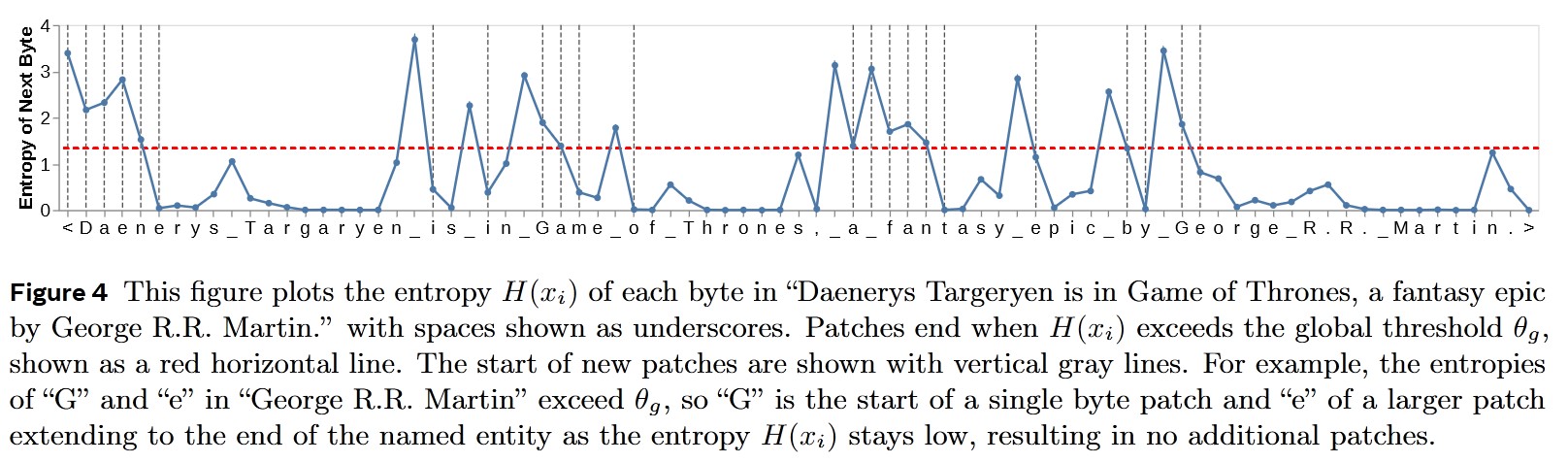
2. Patching: From Individual Bytes to Groups of Bytes
Strided Patching Every K Bytes - The simplest way to transform bytes into patches is by using a fixed size \( k \). However, this method has two drawbacks: computation is not dynamically allocated, and similar bytes may have different representations depending on where the word is split.
Space Patching - In this method, a new group is created after every space character. While this ensures consistent representation of bytes, it still lacks dynamic computation allocation.
Entropy Patching - This novel method, introduced by the authors, uses entropy to determine group boundaries. To compute the entropy of the next byte, the input text is processed by a small LLM, which outputs a probability distribution. Two strategies for boundary definition are proposed:
- A new boundary is created if the entropy exceeds a globally defined threshold.
- A new boundary is created if the rate of change in entropy between two tokens exceeds a globally defined threshold.
Most modern LLMs use Byte Pair Encoding, which creates tokens based on frequently occurring subwords. BLT improves upon this by being an incremental patcher—only depending on the last two bytes—allowing it to operate during inference.
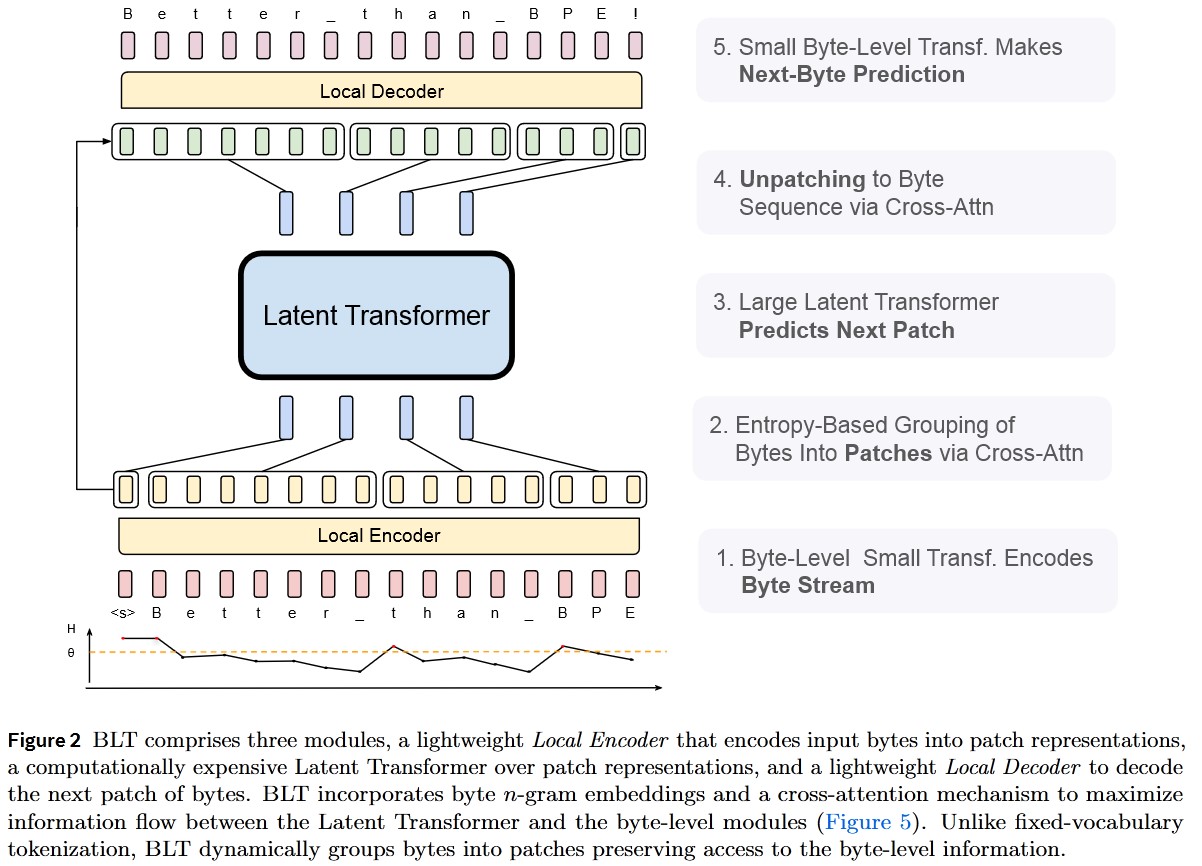
3. BLT Architecture
The BLT architecture comprises three models:
- A large model that operates on the computed patch representations.
- An encoder that transforms bytes into patches.
- A decoder that transforms patches back into bytes.
The encoder works by embedding the input sequence of bytes into a matrix, which can be augmented with additional information, such as positional encodings. A series of attention layers then transforms this matrix into the patch representation using cross-attention mechanisms that focus only on the bytes forming a patch.
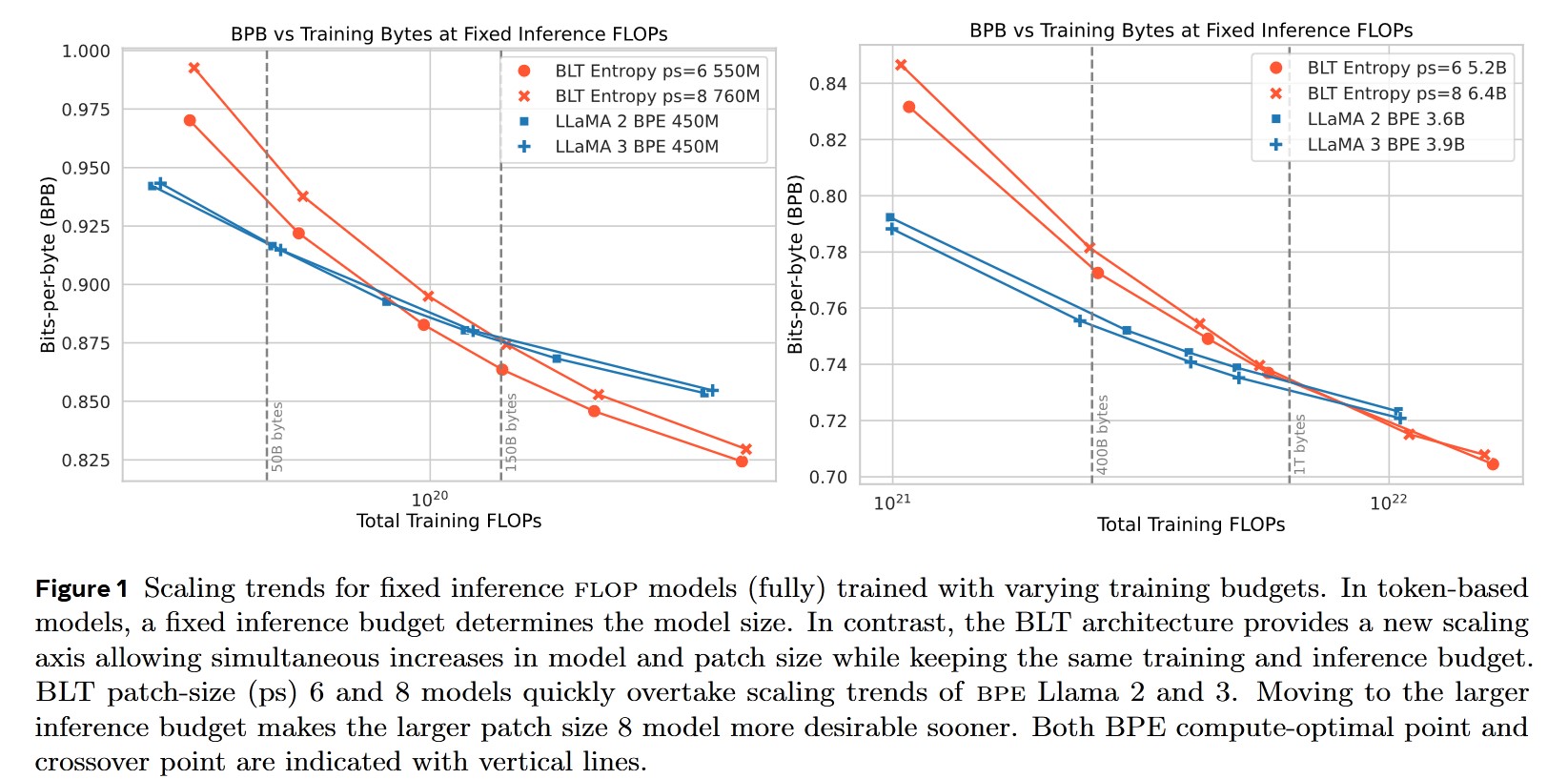
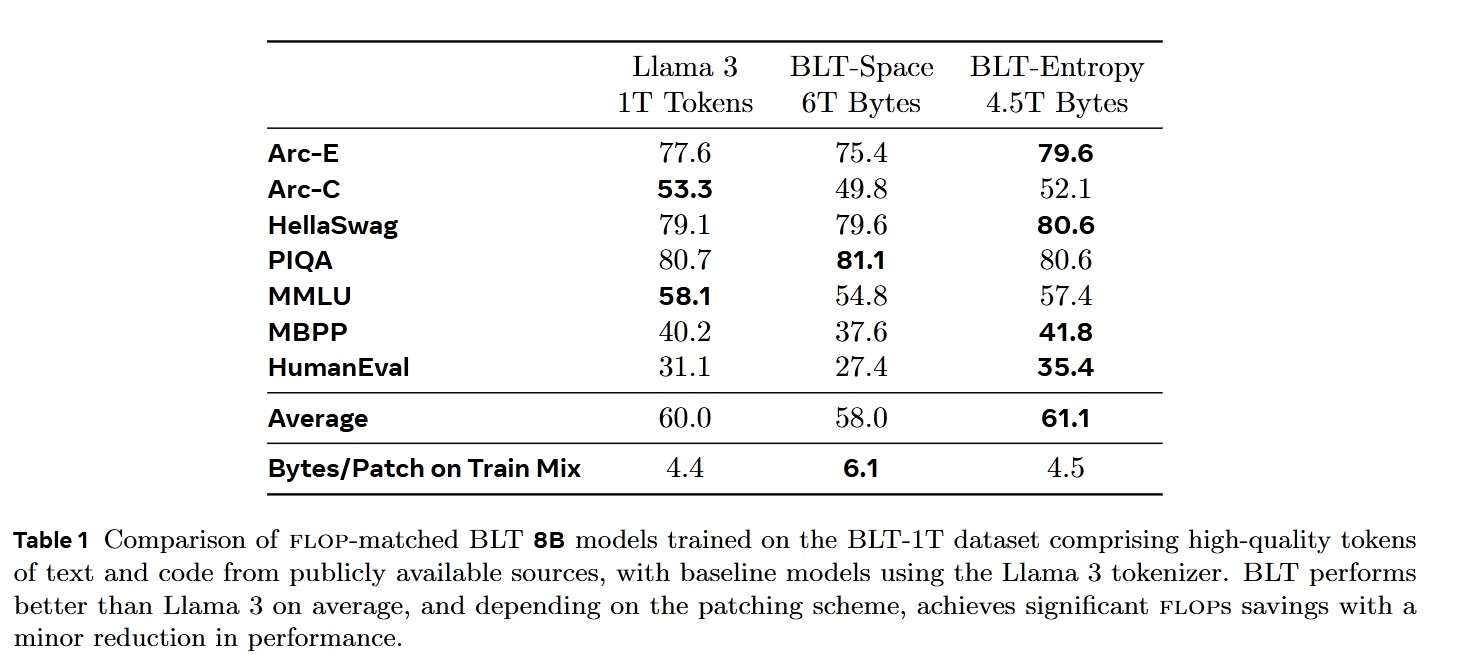
4. Experiments
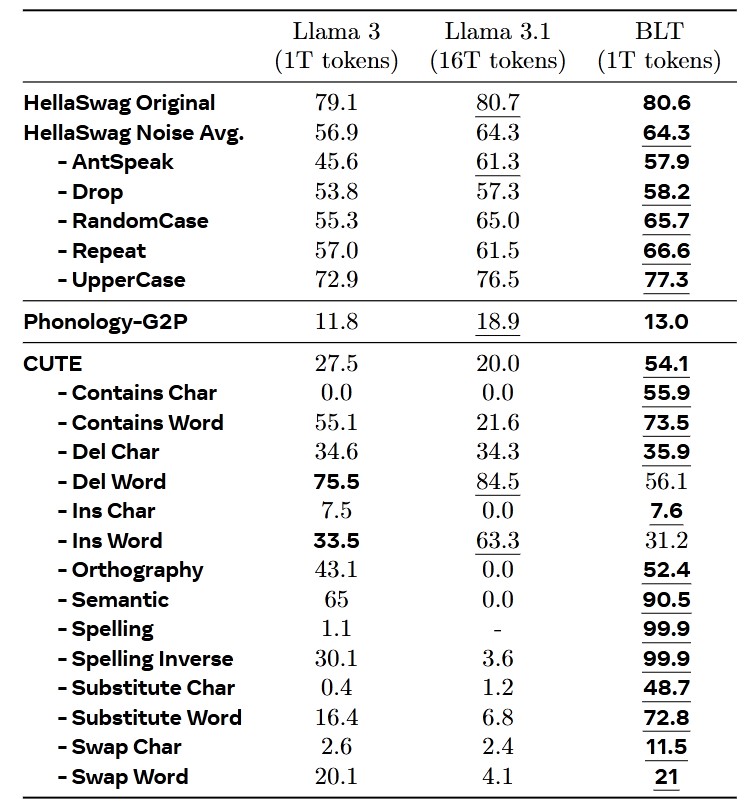
The authors evaluate their architecture using various industry-standard datasets. They also train multiple model sizes to examine how BLT’s scaling compares to regular LLMs. Additionally, noise is introduced in the benchmarks to test BLT’s robustness.
Instead of relying on traditional perplexity metrics (which work only on tokens), they use Bits-Per-Byte (BPP) as the performance measure.
To ensure fair comparisons, the training FLOPS for BLT are matched with those of other models in the benchmarks.
5. Conclusion
BLT appears to be a promising new architecture and encoding method, though further research is needed.
 reply via email
reply via email