Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
February 1, 2024 | 592 words | 3min read
Paper Title: Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Link to Paper: https://arxiv.org/abs/2201.11903
Date: 28. January 2022
Paper Type: NLP, LLM, prompting
Short Abstract:
The paper explores the concept of Chain of Thought, a sequence of intermediate reasoning steps that significantly enhances the reasoning abilities of Large Language Models (LLMs).
1. Introduction
Chain of thought is an combination of two key ideas:
- Arithmetic reasoning, can benefit from using some kind of rationale which lead to the final answer.
- LLM’s have the ability of in context learning, this means without changing their parameters, by using multiple examples in their prompts.
In essence, Chain of Thought represents a series of reasoning steps in natural language leading to the solution of a given task.
2. Chain-of-Thought Prompting
Chain of Thought (CoT) draws inspiration from human thought processes, where complex tasks are broken down into smaller problems, and each sub-problem is addressed through a series of steps before arriving at the final solution.
Key benefits of CoT include:
- Decomposing problems into smaller steps, allowing the model to allocate more computational power to complex components.
- Enhancing interpretability of LLM behavior, through the reasoning steps.
- Being model-agnostic and straightforward to implement.
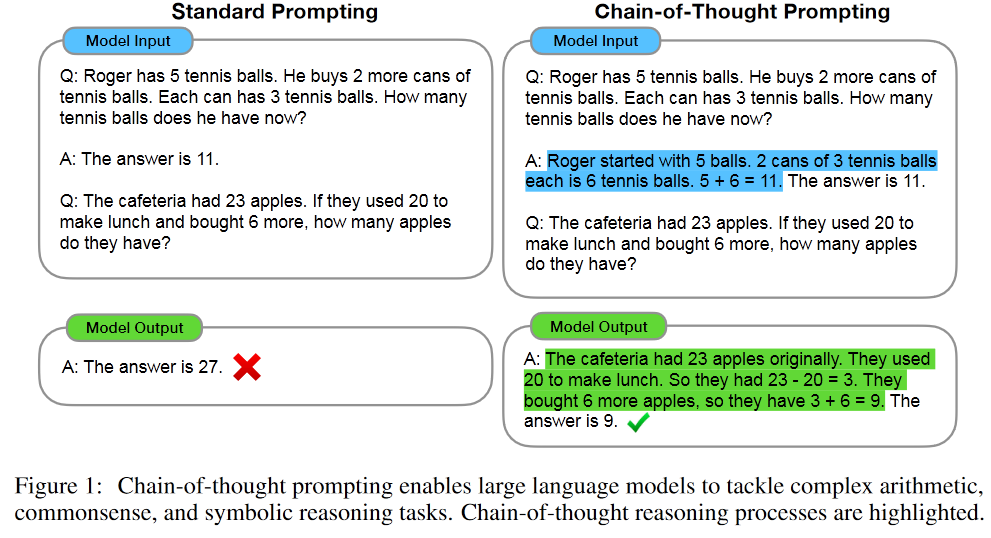
To use CoT on a LLM, one can simply include some examples of CoT sequences(see Figure 1) into the Prompt. Sometimes we additionally, attach the phrase “Think Step for Step” to the input prompt.
3. Benchmarks
For all benchmarks the author use the googles PaLM 540B model in combination with CoT prompting and additionally the GPT model.
For the baseline, they use standard few-shot prompting this means in every prompt a few examples are included, these are formatted like question answer pairs.

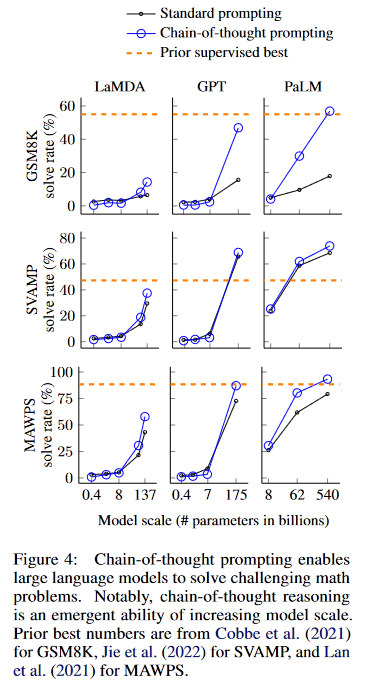
3.1 Arithmetic Reasoning
The Authors explored benchmarks such as GM8K, SVAMP, ASDiV, AQuA, and MAWPS to assess CoT’s impact on arithmetic reasoning.
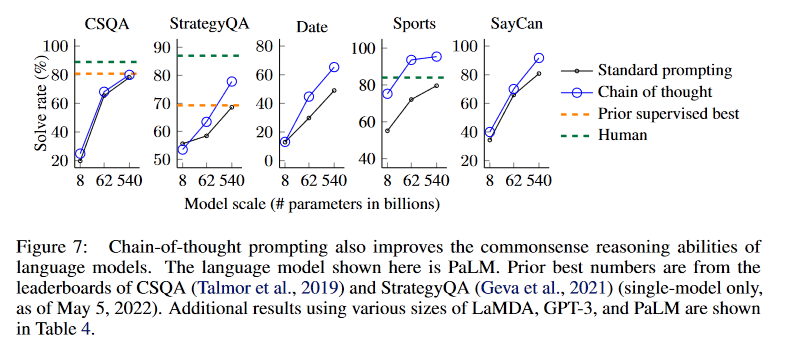
3.2 Commonsense Reasoning
The Authors explored benchmarks including CSQA, StrategyQA, BIG, and SayClan to evaluate CoT in commonsense reasoning.
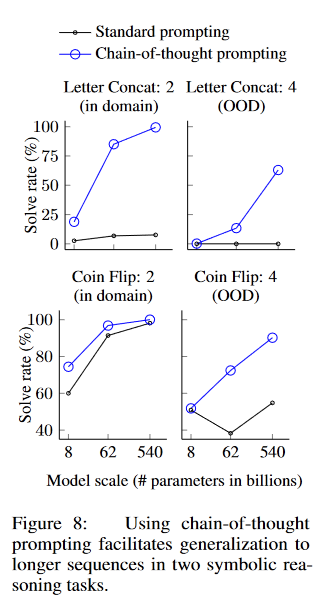
3.3 Symbolic Reasoning
The authors use for symbol reasoning the following two tasks:
- Last letter concatenation: This task asks the model to concatenate the last letters of words in a name.
- Coin Flip: This task asks the model to answer whether a coin is still heads up after people either flip or don’t flip the coin.
3.4 Results
The main takeaways from the results are:
- CoT does not positively impact the performance of smaller models.
- CoT does positively impact the performance of bigger models.
- CoT is an emergent ability of model scale.
- Smaller models, lead to illogical chains of thought.
4. Ablation: Trying other prompting methods
The Author tried to use the following alternative prompting methods:
- Equation only: Where the model is prompted to output only a mathematical equation before giving the answer, based on the intuition that CoT might be good because it produces equations that the model can evaluate.
- Variable compute only: The authors test a configuration where the model is prompted to output a only sequence of dots (. . .) equal to the number of characters in the equations, based on the intuition that CoT might be good because it has more time for computation.
- Chain of thought after answer: Where the chain of thought prompt is only given after the answer, based on the intution that CoT might be good becasue it allowes the mdoel better acces to relevant knowledge.
All of these variants perform the same or worse as the baseline result.
5. Conclusion
Chain of Thought emerges as an intriguing technique promising substantial performance gains, with the added advantage of being easy to implement and use.
 reply via email
reply via email