Comparison of Various Learning Rate Scheduling Techniques on Convolutional Neural Network
October 26, 2025 | 502 words | 3min read
Paper Title: Comparison of Various Learning Rate Scheduling Techniques on Convolutional Neural Network
Link to Paper: https://ieeexplore.ieee.org/document/9087167
Date: 07 May. 2020
Paper Type: Training-Technique, Hyperparameter, Deep-Learning
Short Abstract: In this paper, the authors compare various learning rate schedulers to determine which one performs best.
1. Introduction
Deep neural networks have performed well on a wide range of problems. However, one major challenge remains — the tuning of hyperparameters. Hyperparameters are settings that must be explicitly defined to guide a machine learning algorithm in the right direction. They cannot be learned automatically and need to be carefully chosen based on experimentation and intuition.
When training a neural network, we seek to minimize the loss between predicted and actual values. During the backward pass, the gradient of the loss is used to update the model’s weights. One important hyperparameter in this process is the learning rate, which determines how quickly or slowly the parameters are updated.
There are different strategies for selecting the initial learning rate — for instance, choosing a random value, or starting with a high learning rate and gradually lowering it over time. This paper investigates the latter approach: how the learning rate can be changed during training, and how various scheduling techniques compare to each other.
2. Learning Rate Tuning Mechanisms
The paper compares six different techniques:
- Constant learning rate: The learning rate is fixed from the beginning and remains unchanged. The optimal value must be found through experimentation.
- Step decay learning rate: Also known as learning rate annealing. Training begins with a relatively high learning rate, which is then reduced at fixed intervals (for example, after every few epochs). The intuition behind this approach is that early in training we want to move quickly across the loss landscape, while later we prefer smaller steps to explore deeper and narrower minima.
- Exponential decay learning rate: Similar to step decay, but instead of discrete reductions every few epochs, the learning rate decreases continuously and exponentially over time.
- Differential learning rate: Often used during fine-tuning, where lower layers (which contain more general features) are updated with a smaller learning rate, while higher layers (which are more task-specific) use a larger learning rate.
- Cyclical learning rate: The learning rate varies between two boundaries — a lower and an upper limit. This variation can follow a triangular, exponential, or cosine pattern. The idea is to allow the model to periodically explore different regions of the loss surface and escape shallow minima.
- Stochastic gradient descent with warm restarts (SGDR): This is a more aggressive annealing schedule. The learning rate follows a cosine function, gradually decreasing over time, and then restarts from the initial value after a fixed number of epochs — hence the term warm restarts.
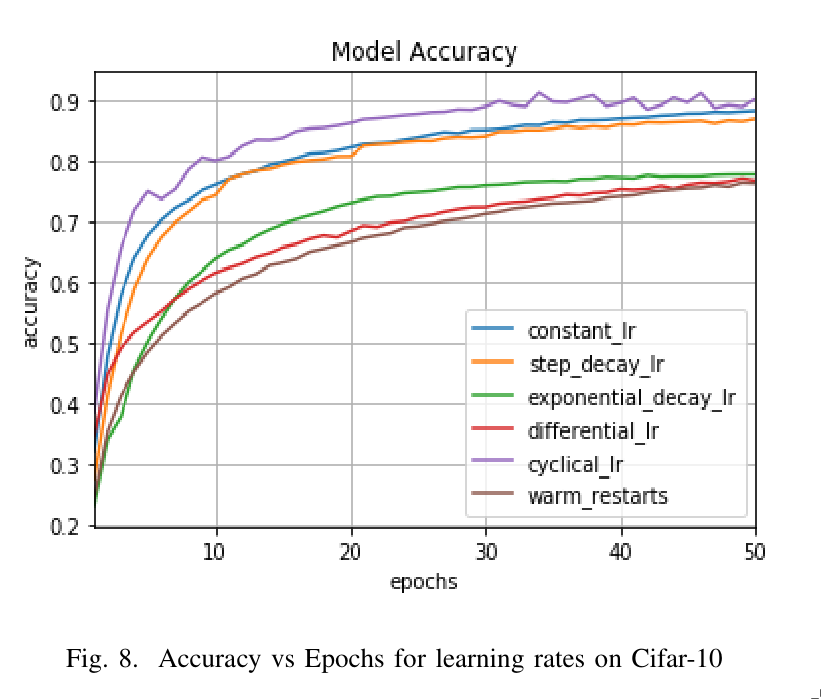
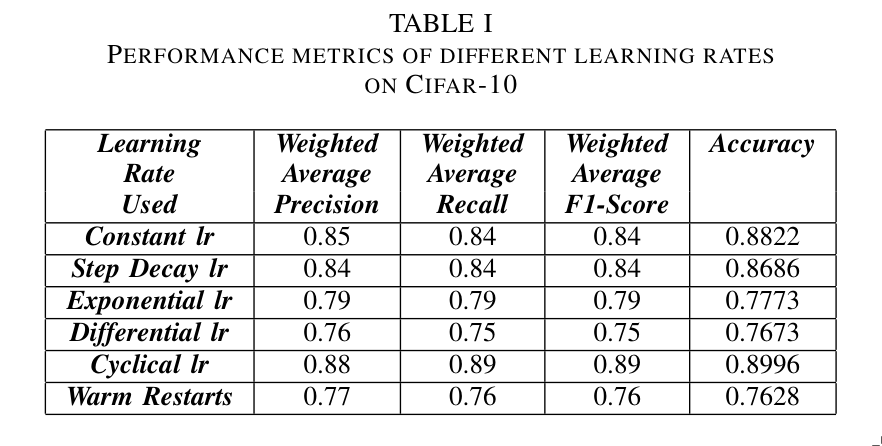
3. Experiments
The experiments were conducted on the CIFAR-10, CIFAR-100, and MNIST datasets using a convolutional neural network (CNN).
4. Conclusion
It appears that the cyclical learning rate scheduler performs the best on these specific datasets and architectures, providing faster convergence and improved accuracy compared to the other methods.
 reply via email
reply via email