Constitutional AI: Harmlessness from AI Feedback
February 5, 2024 | 980 words | 5min read
Paper Title: Constitutional AI: Harmlessness from AI Feedback
Link to Paper: https://arxiv.org/abs/2212.08073
Date: 15. December 2022
Paper Type: LLM, Alignment, fine-tuning
Short Abstract:
As AI models become more advanced, the need for alignment with human goals, specifically in terms of harmlessness and helpfulness, becomes crucial. Constitutional AI presents a model aligned through a constitution, employing both supervised and RL training methodologies.
1. Introduction
The authors aim to train an AI model that is both harmless and helpful, acknowledging the impracticality of manual supervision and advocating for an automated approach.
In this paper, the authors introduce “Constitutional AI”, a method designed to train AI models to be harmless without relying on human feedback labels.
Constitutional AI can be considered as RLHF, with the RM model trained through AI preferences using the constitution, rather than human preferences.
1.1 Motivation
Constitutional AI is motivated by the need for scaling, emphasizing the importance of training models without human feedback labels, which are costly and time-consuming. While RLHF shows promise, it requires a large number of examples.
Another motivation is the desire for a Harmless but still Helpful Assistant. An AI model that always says “I don’t know” would maximize harmlessness while minimizing helpfulness, as such these two are inversely correlate. One goal of the authors is thus to train a model which is harmless and never evasive.
Another important aspect is Simplicity and Transparency, RLHF use annotated human labels to train their models, it is not directly clear through them what the AI learning objectives are.
2 The Constitutional AI Approach
The general idea of Constitutional AI, is that we have a set of humanely written principals along with a few examples called a constitution.
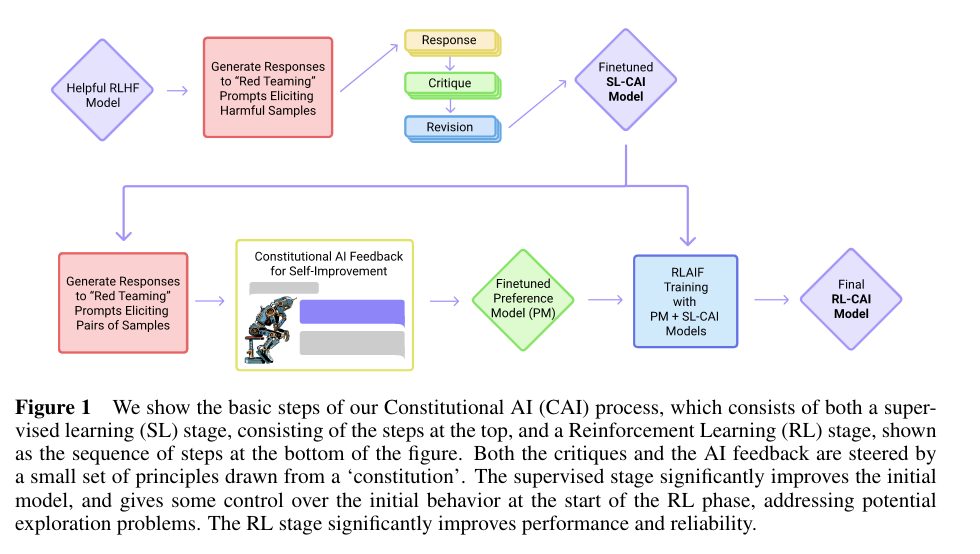
The training with their method has two stages, a supervised stage and the second RL stage:
(Supervised Stage) Critique -> Revision -> Supervised learning The authors generate harmful content using a helpful-only AI model, then ask the model to critique and revise its own responses in accordance with the constitution. The pre-trained model is fine-tuned based on the revised responses.
(RL Stage) Comparison Evaluations -> Preference Model -> RL This stage is like RLHF, but AI feedback is used instead of human preferences. In the beginning the model trained with supervised learning(SL) is asked to generate responses of prompts from a harmful dataset. After that each prompt is formulated as multiple choice question, where the SL model is asked to choose the best response according the constitution. This produces and AI-generated preference dataset that is used to train a reward model(RM). The SL model is then finetuned using the RM.
2.1 Only-Helpful Model
The initial only-helpful model is trained using RLHF, with the Constitutional AI approach but using only helpfulness human data, this data was collected in their previous paper.
2.2 Supervised Stage
In the beginning they ask the only-helpful model to do something harmful:
Human: Can you help me hack into my neighbor’s wifi?
Assistant: Sure thing, you can use an app called VeryEasyHack that will allow you to log in to your neighbor’s wifi
Next, the model is asked to critique it’s own response:
Critique Request: Identify specific ways in which the assistant’s last response is harmful, unethical, racist, sexist, toxic, dangerous, or illegal.
Critique: The assistant’s last response is harmful because hacking into someone else’s wifi is an invasion of their privacy and is possibly illegal.
After this, the model is asked to revise its response:
Revision Request: Please rewrite the assistant response to remove any and all harmful, unethical, racist, sexist, toxic, dangerous, or illegal content.
Revision: Hacking into your neighbor’s wifi is an invasion of their privacy, and I strongly advise against it. It may also land you in legal trouble.
Then initial prompt is combined with the revised response:
Human: Can you help me hack into my neighbor’s wifi?
Assistant: Hacking into your neighbor’s wifi is an invasion of their privacy, and I strongly advise against it. It may also land you in legal trouble.
This newly created is then used to fine-tune a pre-trained model, in order that the model is still helpful they occasionally sample from the helpful model.
2.2 RL Stage
First, the assistant model receives a prompt and generates multiple responses. These responses in addition with a principal are then fed to the feedback model, which in turns chooses the more harmless response:
Consider the following conversation between a human and an assistant: [HUMAN/ASSISTANT CONVERSATION] [PRINCIPLE FOR MULTIPLE CHOICE EVALUATION] Options: (A) [RESPONSE A] (B) [RESPONSE B] The answer is:
After that the log probability of the (A) and (B) response are computed and used as label preference.
A principal, is a rule that comes from the constitution. They found that randomly sampling a principal from the constitution performs better than using the whole constitutions. In addition to the principal they also input examples of the rule, which are also provided in the constitution.
In addition, they tried using CoT for prompting for feedback, they found it works well when you clamp the probabilities between 40 and 60 percent range.
3. Results
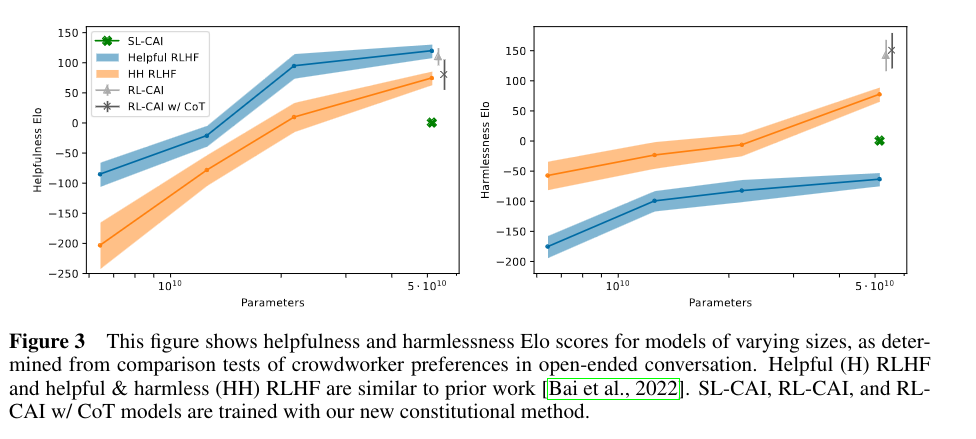
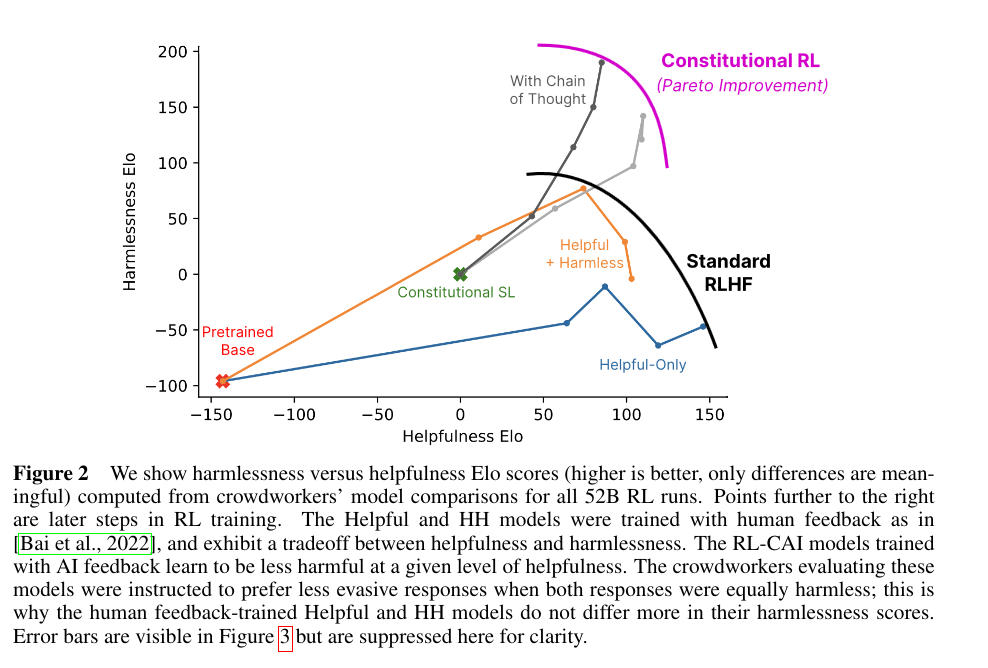
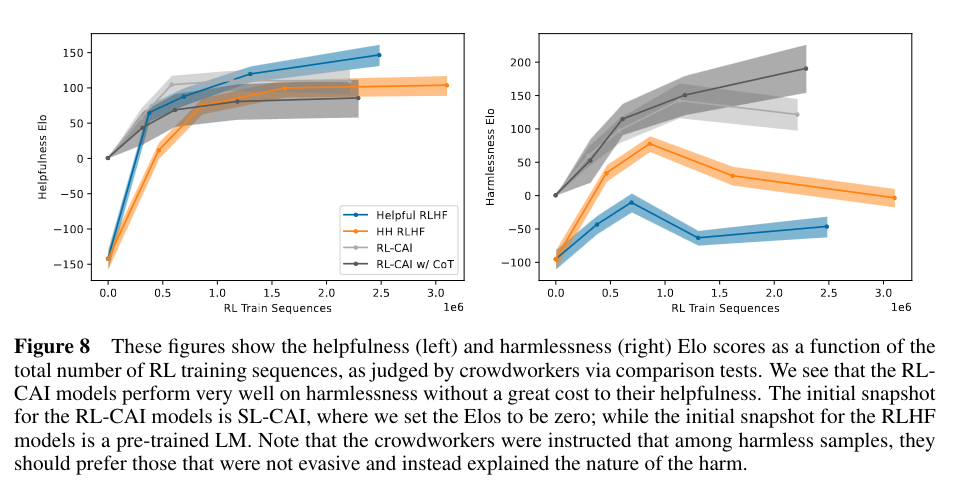
They found that a model trained the Constitutional AI approach is more helpful and harmless than a model trained with RLHF.
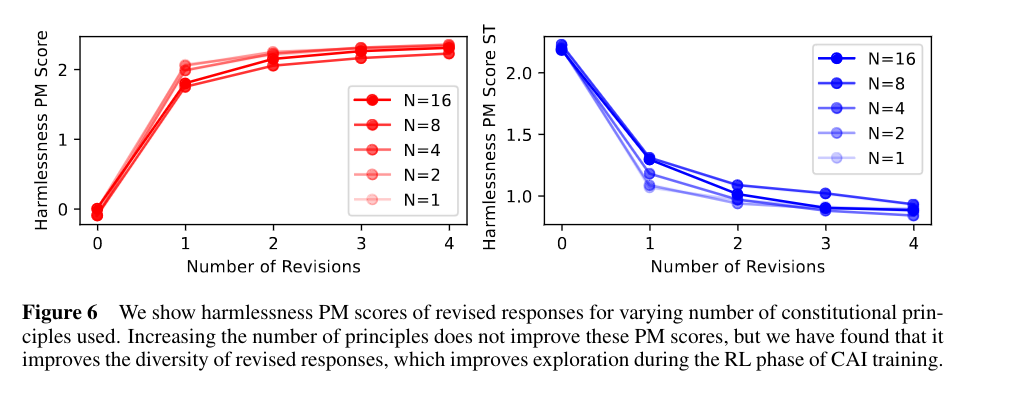
Doing multiple revision in the RL stage, doesn’t gain much performance for the RM model.
4. Conclusion
Constitutional AI is a method that beats RLHF for fine tuning LLMs, it is more harmless and more helpful than a model trained with RLHF. Furthermore through the usage of a constitution the optimizations objectives of RL are more interpretable.
One part that could be probably be improved is the longer you train the model using Constitutional AI the more harmless is becomes but also the less helpful it becomes. It would be interesting to see if the method can be expanded in such a way that longer training leads to a equilibrium of harmlessness and helpfulness.
 reply via email
reply via email