Deep reinforcement learning from human preferences
February 5, 2024 | 639 words | 3min read
Paper Title: Deep reinforcement learning from human preferences
Link to Paper: https://arxiv.org/abs/1706.03741
Date: 12. June 2017
Paper Type: RL, RLHF
Short Abstract:
This paper introduces Reinforcement Learning from Human Preferences (RLHF), a technique that enables RL agents to learn without a direct reward, relying instead on human preferences for their actions.
1. Introduction
Reinforcement learning (RL) has achieved numerous successes in enabling agents to learn how to navigate and solve complex environments, especially when a well-specified reward function is available.
However, there are scenarios where defining a reward function is challenging or even impossible. For example, when training a robot to make scrambled eggs, it’s not straightforward to define a reward function. In such cases, inverse reinforcement learning and behavior cloning can be employed, but they are limited to behaviors easily demonstrable by humans.
Alternatively, direct feedback from humans can serve as a reward function, but this approach is often expensive. RLHF proposes a novel method: learning a reward function from human feedback and optimizing it. This approach aligns with several key principles:
- Enables the agent to solve task for which humans can recognize the desired behavior, but not demonstrate it.
- Scales to large problems.
- Allows the agent to be taught by non-experts.
- Is economical with user feedback data i.e. Requires significant less data than direct human supervision.
The authors test their method on two diverse domains: Atari games and robotics tasks.
2. Method
2.1 Setting and Goal
The RLHF agent interacts with an environment across a sequence of steps. At each step \(i\), the agent receives an observation
$$o_t \in O$$from the environment and performs an action \( a_t \in A \) in response.
In traditional RL, the agent aims to maximize a reward \( r_t \in \mathbb{R} \). In RLHF, a human overseer expresses a preference for a trajectory, which consists of multiple steps of observations and actions. The RLHF agent’s goal is to produce a trajectory preferred by the human.
2.2 RLHF
RLHF employs a deep neural network \(r' \) as a reward function estimator and a current policy \( \pi \), representing a sequence of actions optimizing the reward function estimation.
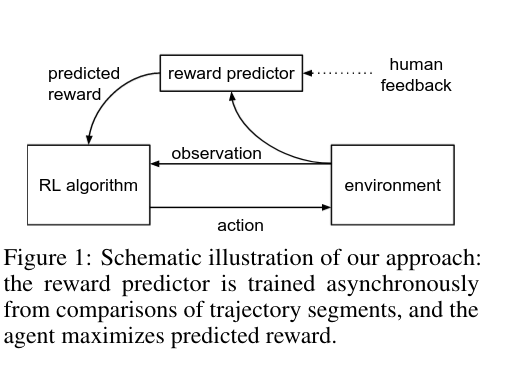
The network updates follow this process:
- The agent executes action \(a\) from policy \(\pi\). \(r'\) estimates the reward based on the action \(a\) and the environment observation. Traditional RL algorithms then update the agent network weights based on the reward \(r'\).
- Subsequently, a random pair of actions is sampled from the current trajectory and presented to a human for preference expression.
- The reward function estimator is updated through supervised learning based on human-expressed preferences.
After receiving the reward \(r'\), the agent can be optimized as in traditional RL settings.
Human preference expression is task and environment-specific. For language models, text may be presented, while for Atari games, short video clips showcasing the agent’s gameplay may be provided. Preferences are then stored in a database.
To optimize the reward function estimator, the authors employ cross-entropy loss between the predicted model loss and the human-provided feedback. Specifically, they use the Bradley-Terry model for estimating score functions between pairwise preferences.
3. Results
3.1 Simulated Robotics
Synthetic labels are generated by selecting trajectories leading to higher rewards down the hill, based on true rewards, instead of being presented to humans.
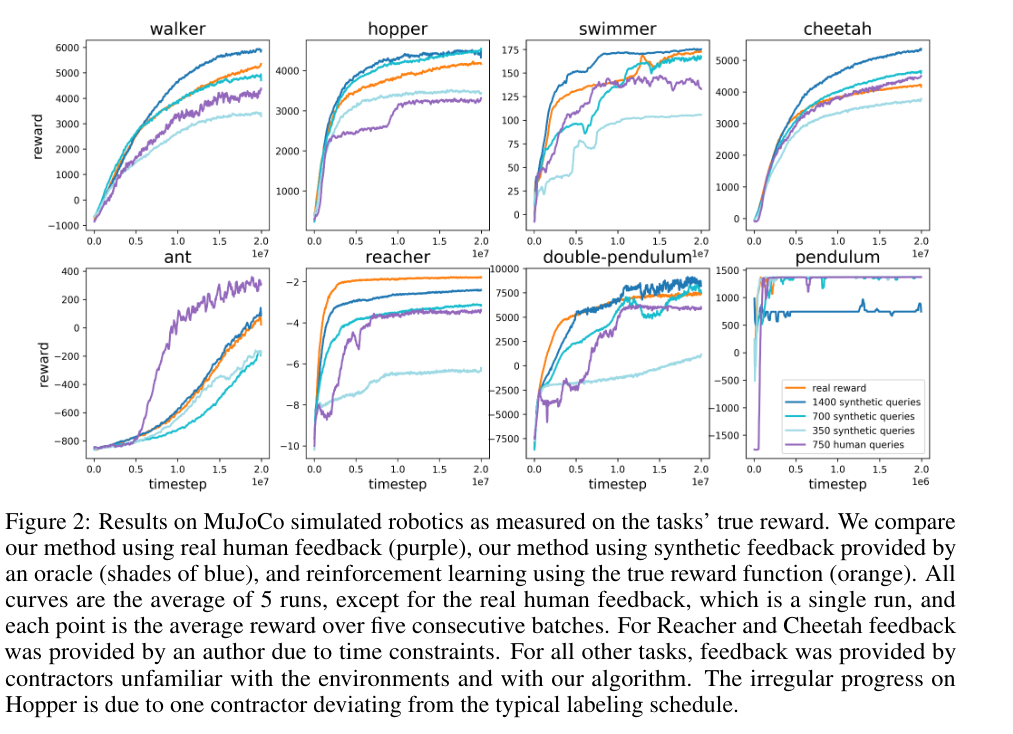
With the reward model trained on 700 labels, the authors achieve performance matching that of a true RL algorithm on all tasks.
3.2 Atari Games
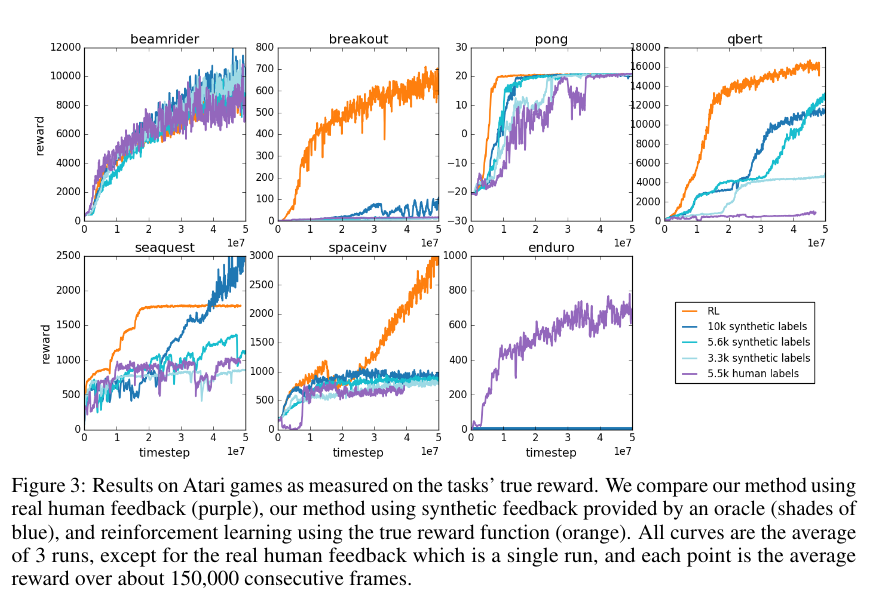
On most games, RLHF performs similarly or slightly worse than a true RL algorithm with true rewards. In some games, RLHF exhibits significant performance disparities, attributed to game-specific reasons.
4. Conclusion
The authors demonstrate that by learning a reward function estimator from human feedback using supervised learning, it is possible to train an RL agent to solve tasks. This approach is particularly beneficial for tasks where defining a reward function is challenging.
 reply via email
reply via email