Efficient Estimation of Word Representations in Vector Space
February 2, 2024 | 613 words | 3min read
Paper Title: Efficient Estimation of Word Representations in Vector Space
Link to Paper: https://arxiv.org/abs/1301.3781
Date: 16. January 2013
Paper Type: NLP, Word-Embedding
Short Abstract:
This paper introduces word2vec, a novel model architecture that facilitates the embedding of continuous vector representations of words.
1. Introduction
If you have an NLP system like a LLM, you first need to train this NLP system. To train it, you need to represent the words from the text on which you want to train as continuous numerical vectors; word2vec accomplishes this.
Before word2vec, most NLP systems treated words as atomic units (e.g., through a one-hot vector encoding). This approach implies no concept of similarity between words, as each word is distinct and not comparable to others.
The goal of word2vec is to learn high-quality word vectors from a vast dataset with billions of words and millions of words in the vocabulary. Furthermore, they aim for the learned word vectors to have semantic meaning, grouping similar words together in the vector space based on shared properties. This semantic meaning, alowss for vector addition expressions like this vector(“King”) - vector(“Man”) + vector(“Woman”) = vector(“Queen”).
2. Model Architectures
Word2Vec utilizes a neural network with two layers. Its input is a text corpus, and its output is a set of vectors representing the words. Although not a deep neural network, word2vec transforms text into vectors comprehensible to deep neural networks.
Feedforward Neural Net Language Mode(NNLM) In NNLM, the neural network comprises input, projection, hidden, and output layers. The input layer encodes $N$ words using a 1-of-V encoding (one-hot encoding), where $V$ is the size of the vocabulary. The projection layer, with dimensionality $N \times D$, then projects the input to the hidden layers. The issue with this model is the high computational complexity of training the neural network back then, which is no longer a concern nowadays.
Continuous Bag-of-Words(CBOW) Mode This model employs the same architecture as NNLM but removes the hidden layer, for lesser computational complexity, and shares the projection weight matrix for all words. It uses the context of the words surrounding the current word to predict a target word.
Continuous Skip-gram Mode In this mode, the model uses the current word to predict the target context. The current word serves as input for the classifier, predicting the word within a certain range before and after the word.
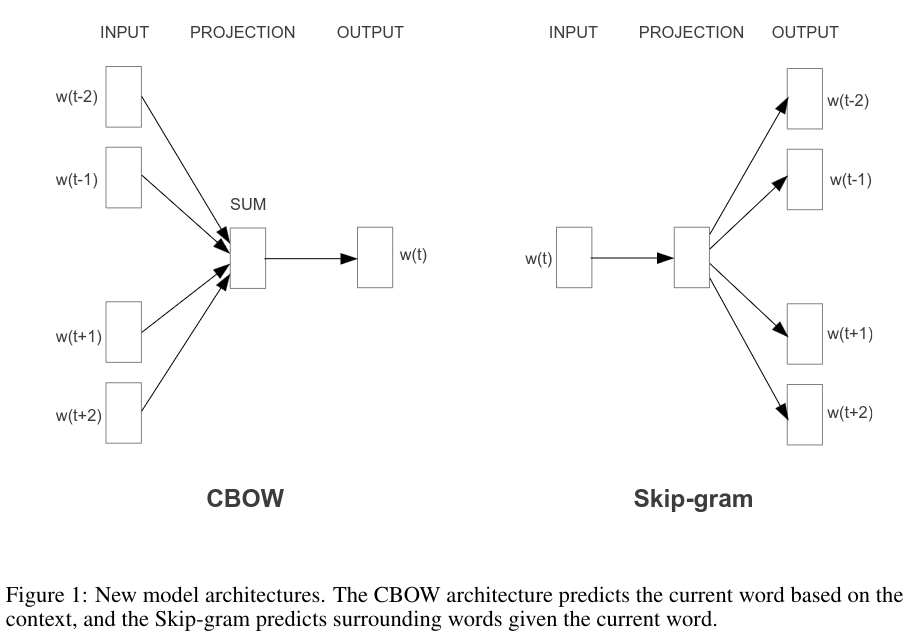
Training Training involves using words as input for the models and calculating the output word by first determining the projection and then the output of the output layer. Afterward, they check if they have predicted the correct word, adjusting the neural network weights based on the loss function.
Inference In inference, the output layer is removed. To obtain the vector representation of a word, the trained model is fed the word, and the output will be the projection layer, serving as the word vector representation.
3. Results
After training the model, it is found that the word vector representations have semantic meaning. For example, the word big is similar to bigger. This enables vector addition in the semantic vector space, computing X = vector(“biggest”) - vector(“big”) and then finding the vector in the space closest to X, using cosine distance, which in this case is X = vector(“small”).
Adding dimensionality to the projection layer or increasing training data doesn’t improve performance beyond a certain point. Only when increased together do they lead to better results.
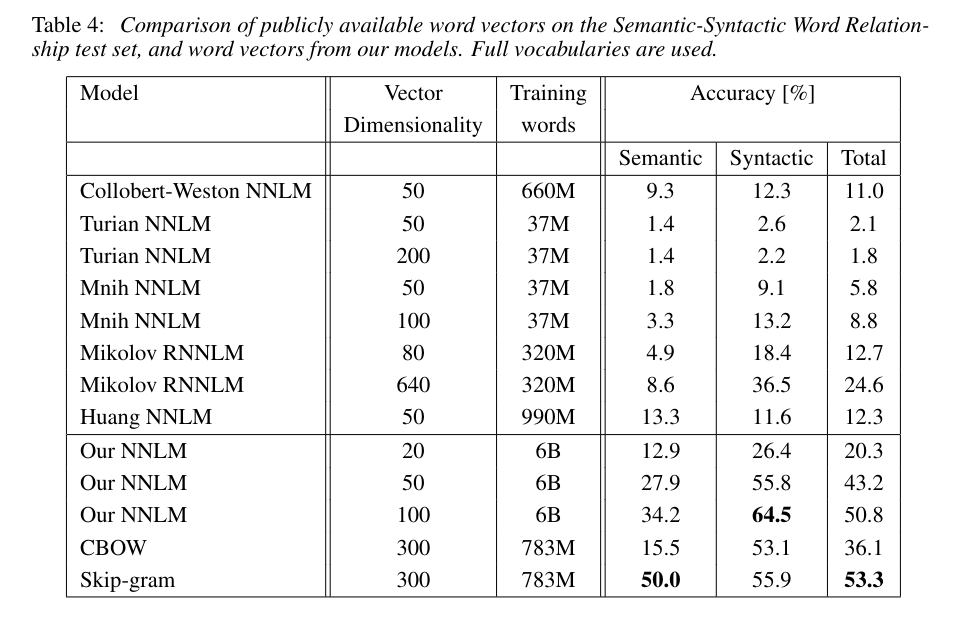
Table 4 indicates that the methods from Word2vec outperform all other techniques from that time by a wide margin.
4. Conclusion
Word2Vec is a highly influential paper that demonstrated the possibility and utility of using neural networks to train word embeddings for later use in NLP systems.
 reply via email
reply via email