Long short-term memory and learning-to-learn in networks of spiking neurons
October 17, 2025 | 376 words | 2min read
Paper Title: Long short-term memory and learning-to-learn in networks of spiking neurons
Link to Paper: https://arxiv.org/abs/1803.09574
Date: 26. March 2018
Paper Type: SNN, Neuromorphic, Meta-Learning, RNN, R-SNN
Short Abstract: In this paper, the authors train recurrent networks of spiking neurons (RSNNs) and compare them to other models. For training, they use backpropagation through time (BPTT) and a synaptic rewiring method called DEEP R. The resulting network is referred to as an LSNN. They also test their architecture on learning-to-learn (L2L) schemes.
1. Introduction
Recurrent networks of spiking neurons (RSNNs) are often used as models to study the human brain. In principle, because of their spiking and temporal characteristics, they should be well suited for that purpose.
However, one difference between our brain and RSNNs is that the brain is much more sparse. To model this, the authors train their RSNN with BPTT and DEEP R—a biologically inspired heuristic for synaptic rewiring. The resulting model is called Long Short-Term Memory Spiking Neural Networks (LSNNs).
They show that this approach performs well on common benchmark tasks such as Sequential MNIST and TIMIT. After that, they demonstrate that their approach can also be applied to learning-to-learn (L2L) schemes.
2. LSNN Model
The LSNN consists of a population R of leaky integrate-and-fire (LIF) neurons (both excitatory and inhibitory), and a second population A of adaptive LIF excitatory neurons whose excitability is temporarily reduced after firing. Both populations R and A receive spike trains from a population X of external neurons.
3. Applying BPTT with DEEP R to RSNNs and LSNNs
To optimize the LSNN, the authors use backpropagation through time (BPTT). To make the model differentiable during the backward pass in training, they replace the Heaviside operation with another function to produce a surrogate gradient.
In addition to BPTT, they use DEEP R to optimize the connectivity matrix—i.e., which neurons are connected to which.
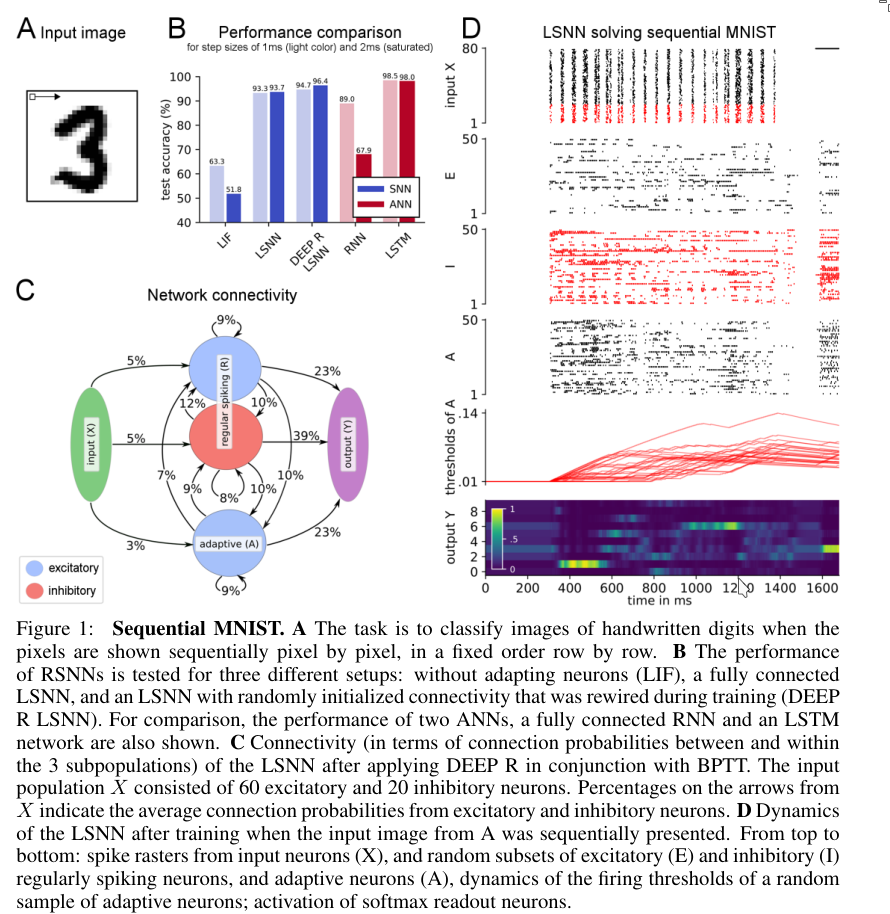
4. Results on Sequential MNIST
Architecture:
- LSNN matches the number of neurons of the baseline LSTM.
- 120 regular spiking neurons and 100 adaptive neurons
- 128 LSTM units
5. LSNNs learn-to-learn from a teacher
Skipped, not relevant for me.
6. LSNNs learn-to-learn from reward
Skipped, not relevant for me.
7. Conclusion
They have demonstrated that their LSNN model works well for supervised training, learning-to-learn, and reinforcement learning.
 reply via email
reply via email