Mistral_7B
January 31, 2024 | 369 words | 2min read
Paper Title: Mistral 7B
Link to Paper: https://arxiv.org/abs/2310.06825
Date: 10. Oct 2023
Paper Type: NLP, finetuning, LLM-training
Short Abstract:
Introduction of the “Mistral 7B” LLM model.
1. Introduction
Mistral 7B deliver high performance while maintaining an efficient inference, it outperforms the previous best 13B Models on all tested benchmarks.
It does this by using grouped-query attention (GQA) and sliding window attention (SWA), GQA accelerates inference speed and SWA allows the Model to work with longer sequences.
Mistral 7B is released under the Apache 2.0 license and can be freely downloaded.
2. Architecture
In vanilla attention, every token can pay attention to every other token this means we have runtime for attention operation of $O(N^2)$. In Sliding window Attention, a given token can only pay attention to the last $k$ tokens. But because we have stacked multiple attention layers on top of each other in the model, we can implicitly attend all tokens.
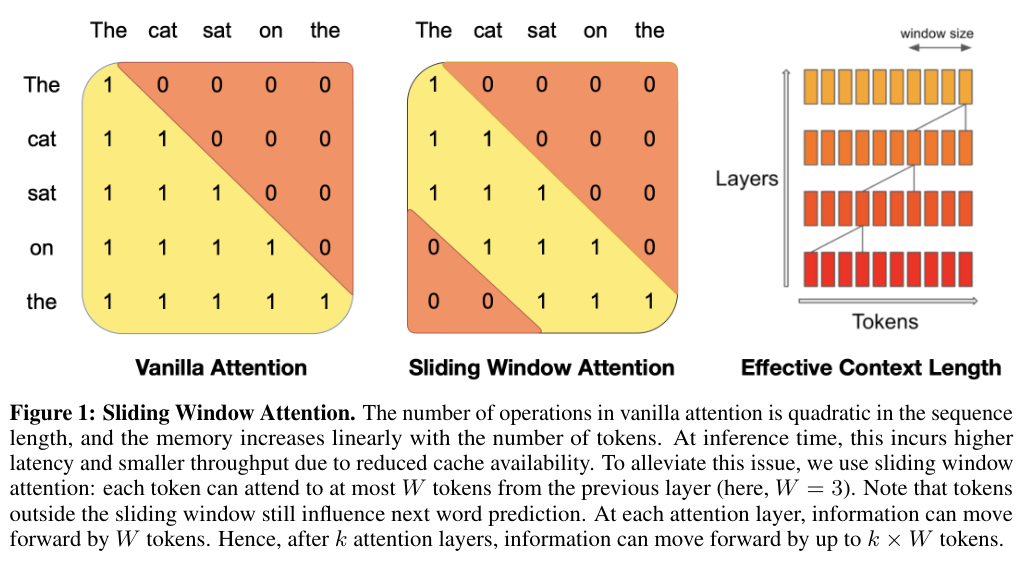
In the figure the y-axis is the input of model, with the beginning of the sentence at the top and the end at the bottom, the x-axis is used to indicate to which tokens the model attends to. Orange shows where attendance is not possible, and yellow where attendance is possible. For Instance we can see that the token “on” can attend to the tokens “The”, “cat”, “sat”, “on” in the vanilla model, but in the SWA model it can’t attend the “The” token. The last image shows how in the SWA model we can still attend all tokens through the use of multiple layers.
3. Results
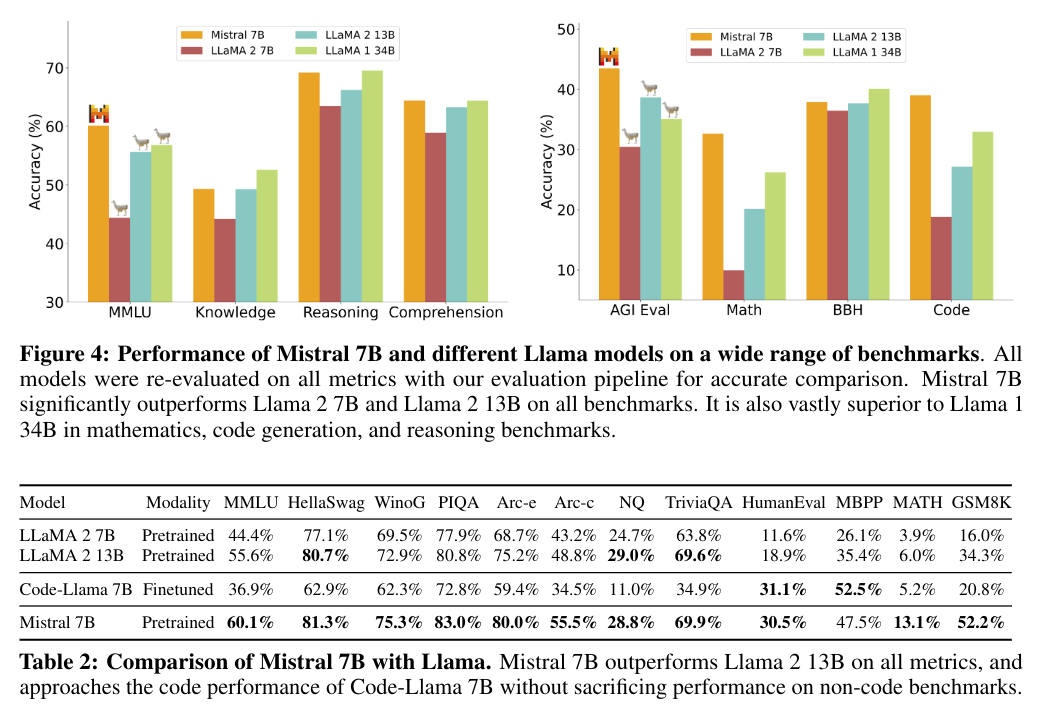
In most benchmarks the Mistral 7B model outperformed the LLaMA 2 13B models. But it has to be said that at that time of the release of this paper, there were already multiple fine tuned models out there, that were a lot better than the LLaMA 2 13B models.
They also trained a fine-tuned Mistral 7B model and compared it to other models with the help of the llmboxing website.
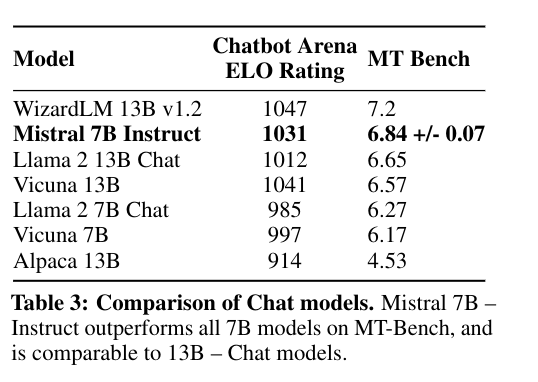
4. Conclusion
This paper researched the usage of sliding window attention in LLM and found that it can allow for big performance gains in smaller LLM models, it would be interesting to see this technique further explored in new models.
 reply via email
reply via email