Take A Shortcut Back: Mitigating the Gradient Vanishing for Training Spiking Neural Networks
October 26, 2025 | 463 words | 3min read
Paper Title: Take A Shortcut Back: Mitigating the Gradient Vanishing for Training Spiking Neural Networks
Link to Paper: https://arxiv.org/abs/2401.04486
Date: 9. Jan 2024
Paper Type: Neuromorphic, Spiking Neural Network, Architecture, Training-Technique
Short Abstract: In this paper, the authors introduce a technique to address the vanishing gradient problem when training spiking neural networks (SNNs). To achieve this, they propose shortcut backpropagation, which transmits gradients directly from the loss function to shallower layers.
1. Introduction
Spiking neural networks (SNNs) are among the most efficient neural network architectures and are therefore used in many different fields.
In contrast to artificial neural networks (ANNs), SNNs use binary spikes as signals. A spiking neuron fires (represented by a 1) if its membrane potential exceeds a predefined threshold; otherwise, it does not fire (represented by a 0). This paradigm results in low energy consumption and can be efficiently implemented on neuromorphic hardware.
However, training SNNs is difficult. Because of their spiking behavior, they are non-differentiable, which makes it impossible to directly train them using gradient-based optimization methods. To overcome this, surrogate gradients are used during the backward pass. These are differentiable functions that approximate the spiking behavior of the network—for example, the tanh or sigmoid functions.
However, a major issue with surrogate gradients is that, since neuron firing is bounded, the surrogate functions are also bounded. As a result, the gradient becomes very small over most intervals, leading to vanishing gradients as it propagates from output to input layers. This prevents effective learning.
To address this problem, the authors propose transmitting the gradient from the loss directly to shallower layers using shortcuts. Specifically, they add multiple shortcut connections from intermediate layers to the network output. These shortcut branches are only used during the backward pass, so they impose no computational burden during inference.
During backpropagation, each layer thus optimizes two losses:
- the global loss propagated through the network, and
- the local loss passed through the shortcut connection.
If too much emphasis is placed on the global loss, the network may fail to overcome vanishing gradients. Conversely, if too much emphasis is placed on the shortcut loss, overall accuracy may degrade.
To balance these effects, the authors use an evolutionary training framework, where more attention is given to the shortcut (local) losses during the early stages of training, and gradually shifted toward the main global branch later.
In essence, this method can be thought of as residual connections that are only used during the backward pass and removed during the forward pass.
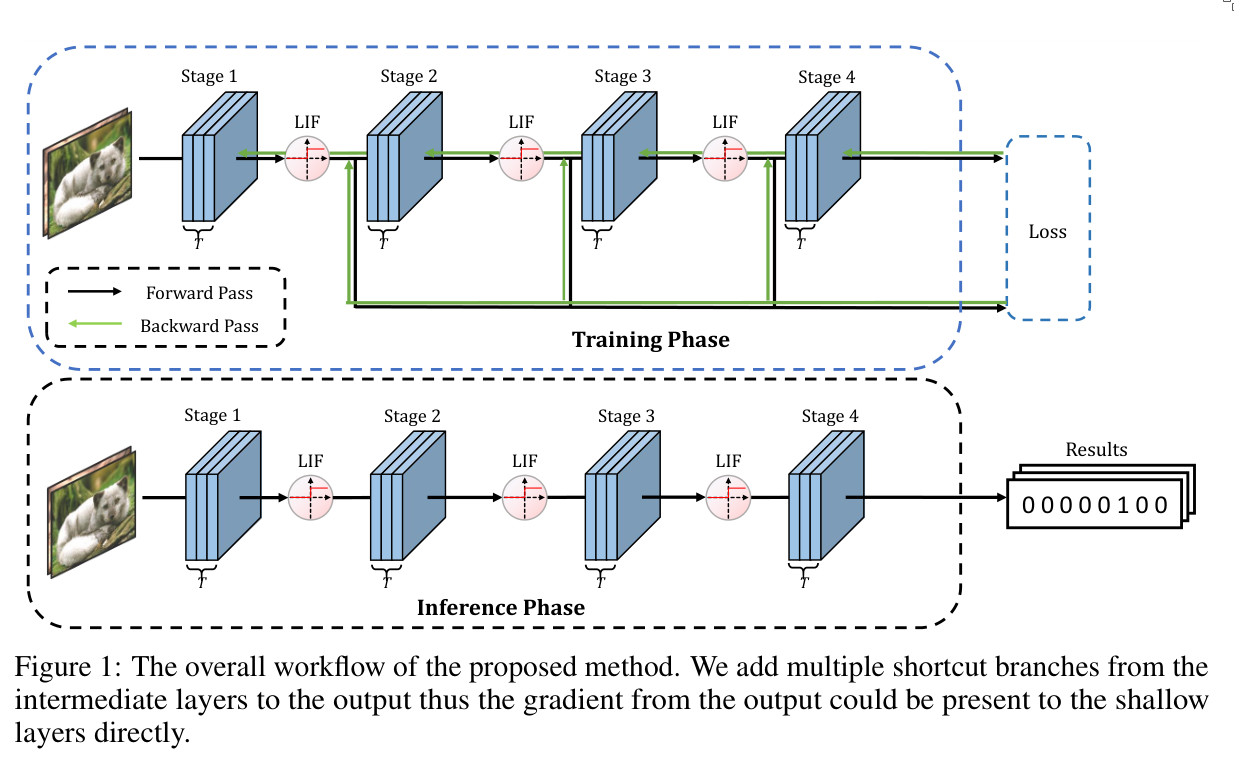
2. Experiments
The experiments were performed on CIFAR-10 (and CIFAR-100), ImageNet, and CIFAR10-DVS datasets.
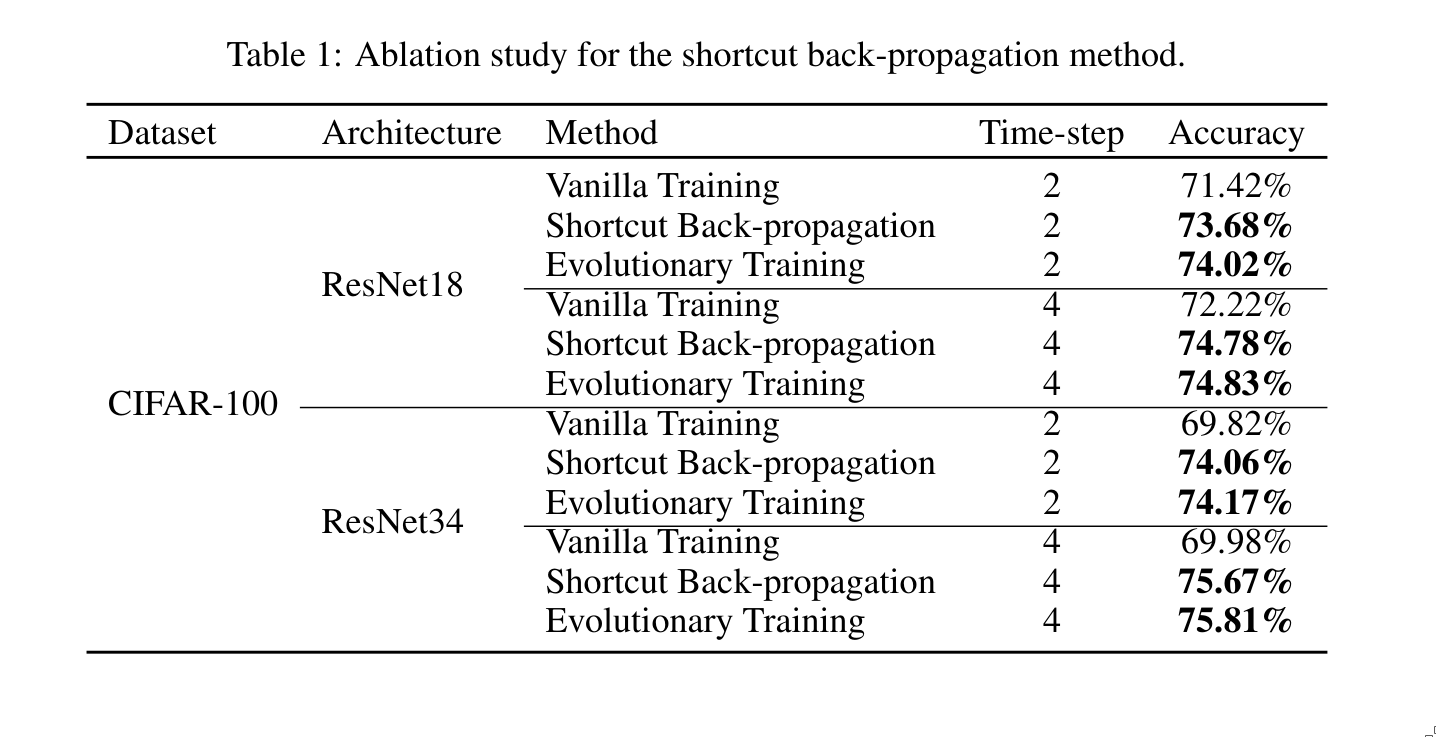
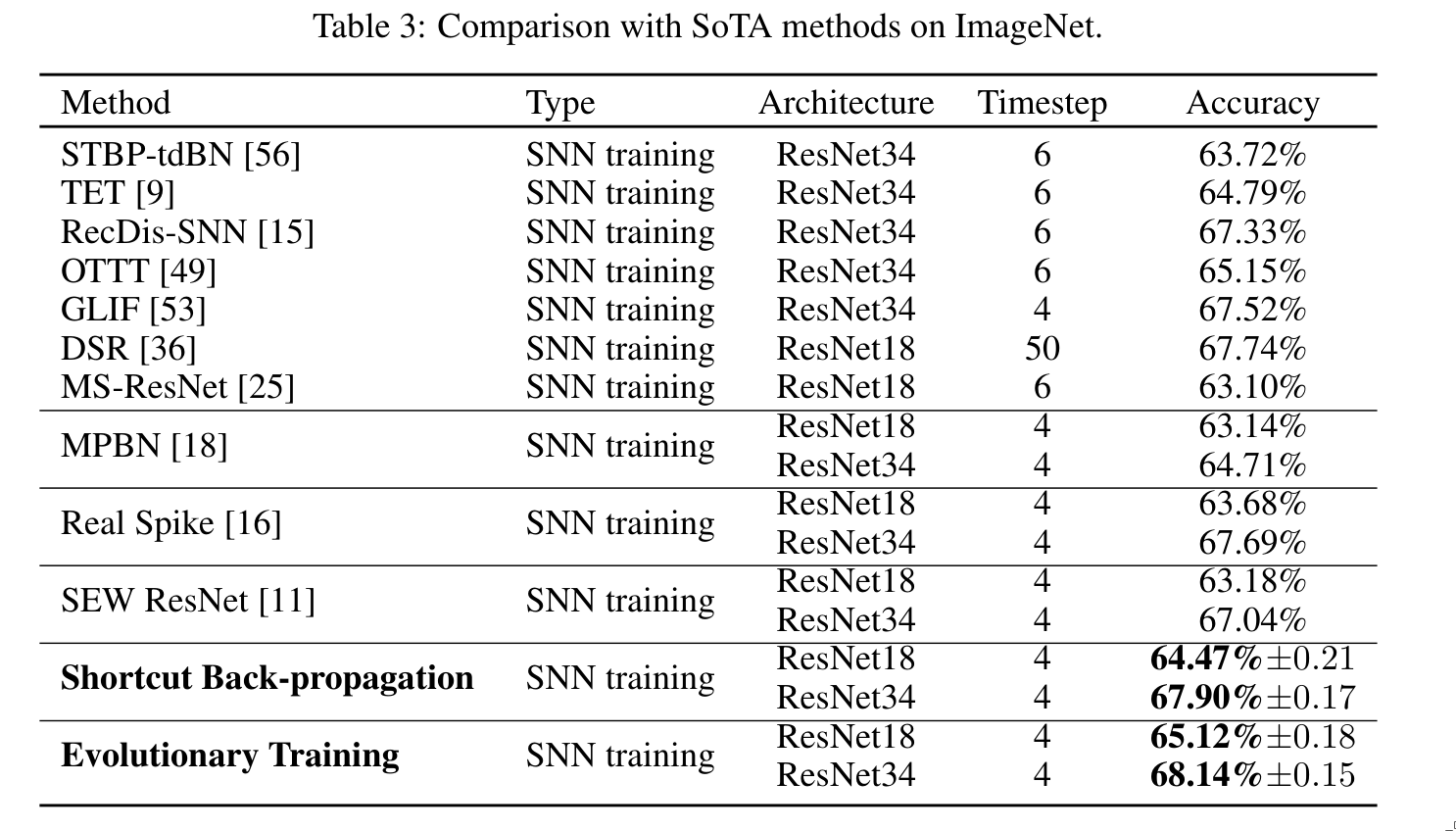
3. Conclusion
The authors present a technique that mitigates the vanishing gradient problem in spiking neural networks. This method introduces no additional burden during inference, and experiments show that it effectively improves training performance.
 reply via email
reply via email