Improving Factuality and Reasoning in Language Models through Multiagent Debate
April 3, 2024 | 619 words | 3min read
Paper Title: Improving Factuality and Reasoning in Language Models through Multiagent Debate
Link to Paper: https://arxiv.org/abs/2305.14325
Date: 23. May 2023
Paper Type: NLP, LLM, RL, LLM-Agents
Short Abstract:
This paper investigates the usage of multiple LLMs as agent that debate between each other, to improve the quality of responses and reduce hallucinations.
1. Introduction
There have been done much research into how to increase the capabilities of LLMs and increase their responses in quality and accuracy. But much of the research has focused on how to improve a single LLM or a single mind.
In this paper, the authors instead propose an approach based on The Society of Mind and multi-agents setting, where multiple LLM instances debate each other responses and their reasoning steps. Specifically, given a query, multiple instances of a LLM generate and output to query and then each instance reads an critics the responses of all the other models.
There are multiple other similar approaches like CoT, I wonder how much of the performance gain is through the exact technique they used and how much is because the LLM just get more time to “think”/calculate.
Their method doesn’t need model-internal information, instead it views the LLMs as black box. Which enables the method to be used on LLMs with public interfaces.
To evaluate the accuracy of their method, they introduce a new benchmark called “Biography” in which LLMs need to create biography for famous scientist. This is also helpful to evaluate hallucinations.
2. Language Generation through Multiagent Debate
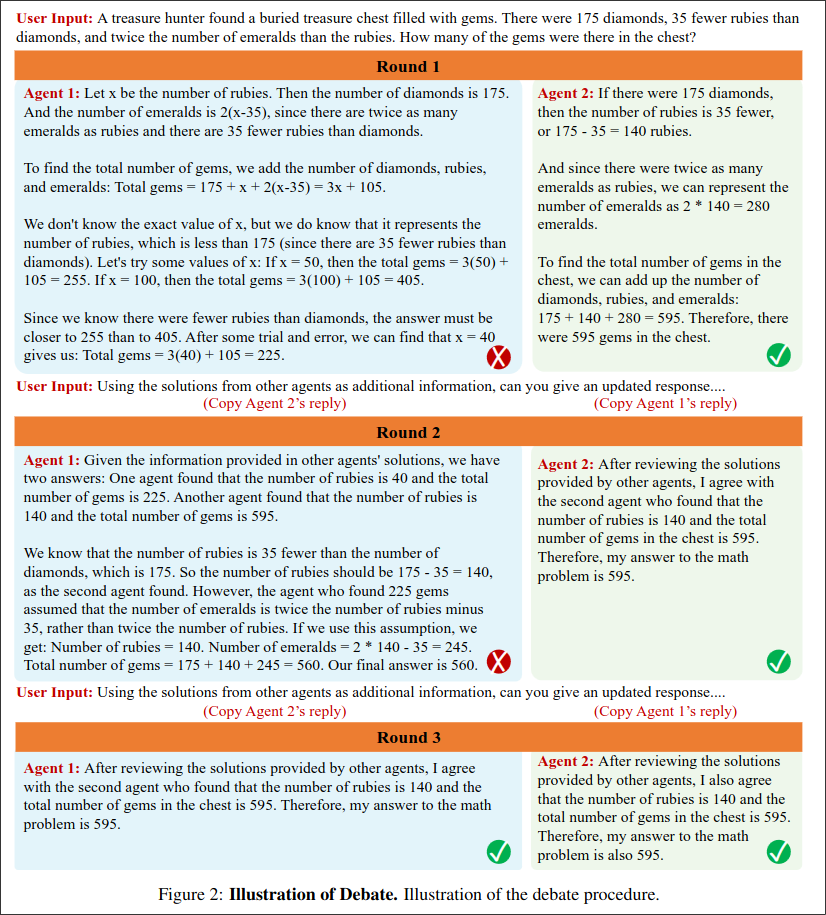
2.1 Multiagent Generation
When thinking about how a human solves a math problem, we often try multiple different paths to the solution and if they agree all, we can be pretty confident that our solution is correct. Similar when writing a biography, you would take multiple sources into consideration, which can provide different facts, or can confirm each other facts. We take advantage of this for our LLMs.
To imitate the above method, we use multiple instances of LLMS. Each response serves as a thought or source of information.
We first let the LLMs respond to the user query, after which a round of debate is initiated between the agent. Where we concatenate the responses of the different agents, give them as context to the agents and ask them to improve their prior response based on the context, by using the prompt from Figure . This process can be iteratively repeated.

2.2 Consensus in Debates
How can we ensure that our LLMs come to a consensus? The debate can be seen as a multi-agent game, where convergence is not guaranteed.
Experimentally the authors find, that most of the times the LLMs do converge on a single answer.
3. Experiments
3.1 Reasoning
Tasks
They evaluate their methodology on increasingly harder benchmarks:
- Arithmetic, solving simple arithmetic expression.
- GM8K, solving mathematical reasoning tasks.
- Chess Move Prediction, predict the next best chess move.
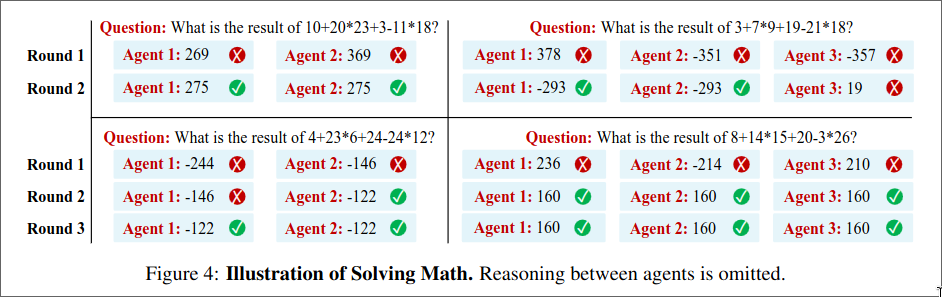
They compare three different methods:
- Directly producing the output
- Generate and then Self-Reflect on their responses
- Using Multiple agents and majority voting
They evaluate in zero-shot setting and use chatGPT as base model.
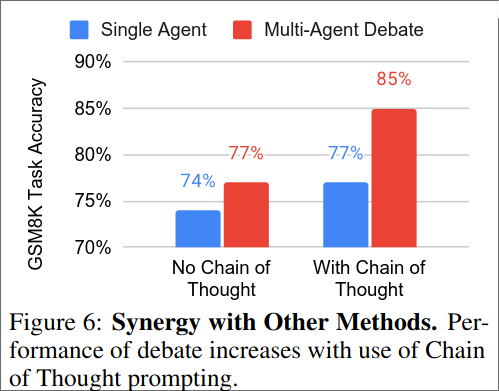
In addition they also find that multi-agent generation has compatibility with other methods such as CoT.
3.2 Extracting Information
Tasks
They evaluate their methodology on three different benchmarks:
- Biographies, accurately generating biographies.
- MLMU, for factual knowledge.
- Chess Move Validity, an agent is given a set of next moves and must make a valid one. This investigates hallucinations.

3.3 Ablation Study
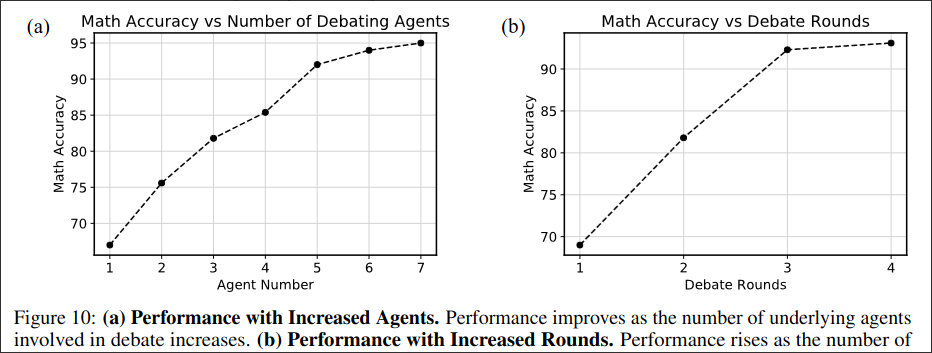
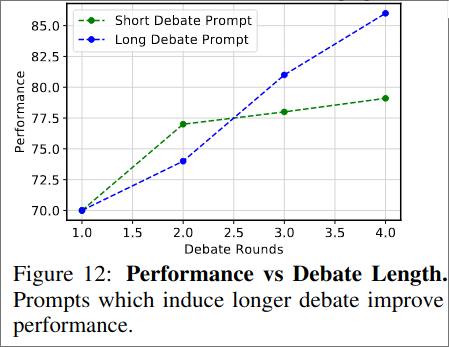
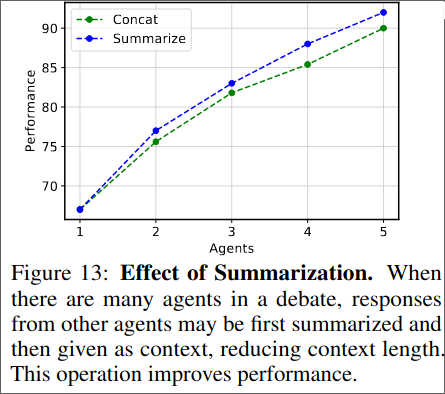
Besides ChatGPT they also try Bard as base model and find it also improves the performance of the Bard Model.
4. Conclusion
This paper presents a method to increase the performance of LLMs through debate, they find that the method helps performance in various tasks.
 reply via email
reply via email