One-Shot Online Testing of Deep Neural Networks Based on Distribution Shift Detection
May 7, 2026 | 680 words | 4min read
Paper Title: One-Shot Online Testing of Deep Neural Networks Based on Distribution Shift Detection
Link to Paper: https://arxiv.org/abs/2305.09348
Date: 16. May 2023
Paper Type: Neuromorphics, Circuits, Fault Detection
Short Abstract: The paper proposes a “one-shot” online testing method for deep neural networks (NNs) implemented on memristor-based computation-in-memory (CiM) hardware. The goal is to detect hardware faults or analog variations using only a single test input (one forward pass). Instead of checking individual weights or using many test patterns, the method detects changes in the output distribution of the network.
1. Introduction
Deep learning accelerators built with memristive devices (e.g. Resistive Random-Access Memory (ReRAM), Phase Change Memory (PCM), Spin-Transfer Torque MRAM (STT-MRAM)) are:
- energy-efficient
- highly parallel
- suitable for edge AI
But they suffer from:
- stuck-at faults
- read/write disturbance
- manufacturing variability
- thermal/runtime noise
These faults can degrade inference accuracy, which is critical in safety applications. Terefore, testing such hardware systems is crucial to ensuring their reliability and correct functionality, especially in safety-critical applications.
Traditional approaches:
- require many test vectors or training data
- are invasive or require retraining/backdoors
- cause long downtime
- do not scale well to large CNNs
This paper proposes a new one-shot testing method, in which the NN can be treated like a black box, that is fast, needs only a single testing vector and archives consistently 100% test coverage.
2. Preliminaries
Memristive devices can be arranged into crossbar arrays, with each cross point consisting of a memristive device. Therefore, the weighted sum computation required for the inference stage of the NN can be carried out directly in the memory by leveraging Ohm’s Law (V = IR) and Kirchhoff’s Current Law at a constant O(1) time without any data movement between the processing element and the memory.
Ultimately, an Analog-to-Digital Converter (ADC) circuit digitizes the sensed currents. After that, other computations in the digital domain, e.g., bias addition, batch normalization, and non-linear activation operations are undertake.
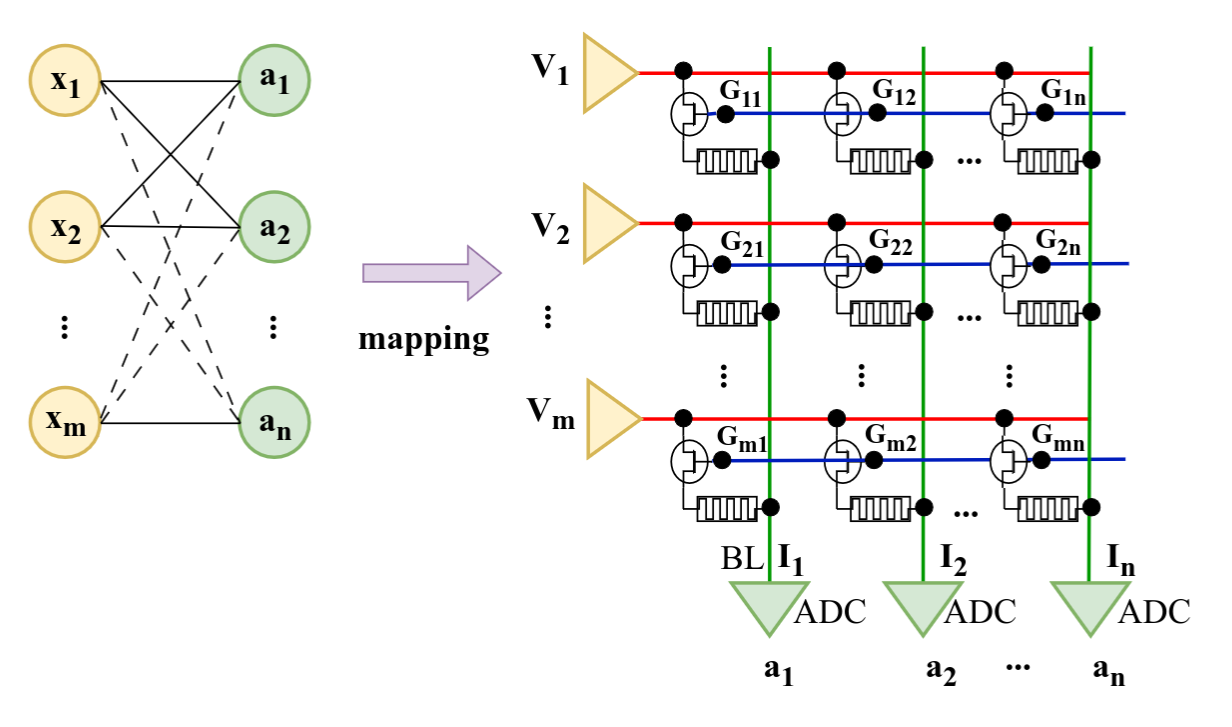
3. Methodology
3.1 Motivation
Observation:
Faults in memristive weights → changes in activations → changes in final output distribution
So instead of testing weights directly, they:
- Feed a single specially optimized input
- Observe the NN output distribution
- Compare it to an expected “normal” distribution
3.2 Deviation Detection Method
Force the NN output to behave like a unit Gaussian distribution:
- mean ≈ 0
- variance ≈ 1
This is done using a specially optimized input vector. This makes it easy later to detect deviation from it.
They compute divergence between:
- expected output distribution N
- observed output distribution N'
using Kullback–Leibler divergence:
- If divergence > threshold → fault detected
- Otherwise → system considered healthy
3.3 One-shot test vector generation
They train a single input image-like tensor using gradient descent so that:
- it produces a standardized output distribution across models
- it maximizes sensitivity to faults
Key properties:
- only one test input
- no need for training data
- works across different architectures
The “test vector” is: an input image-like tensor (shape like [H, W, C]), initialized randomly (Gaussian noise or even real stock images), then optimized using gradient descent. The goal of the training is not accuracy, but forcing the output to become standard Gaussian-like structure. The network is not trained, the input is trained.
Process:
- Start with random input image \( \bar{x} \)
- Forward pass through the network → get output \( \hat{y} \)
- Compute loss:
- how far output is from desired statistical target
- KL-Divergence is used
- Backpropagate gradients to the input
- Update the input image:
- \( \bar{x} \leftarrow \bar{x} - \alpha \nabla L \)
- Repeat
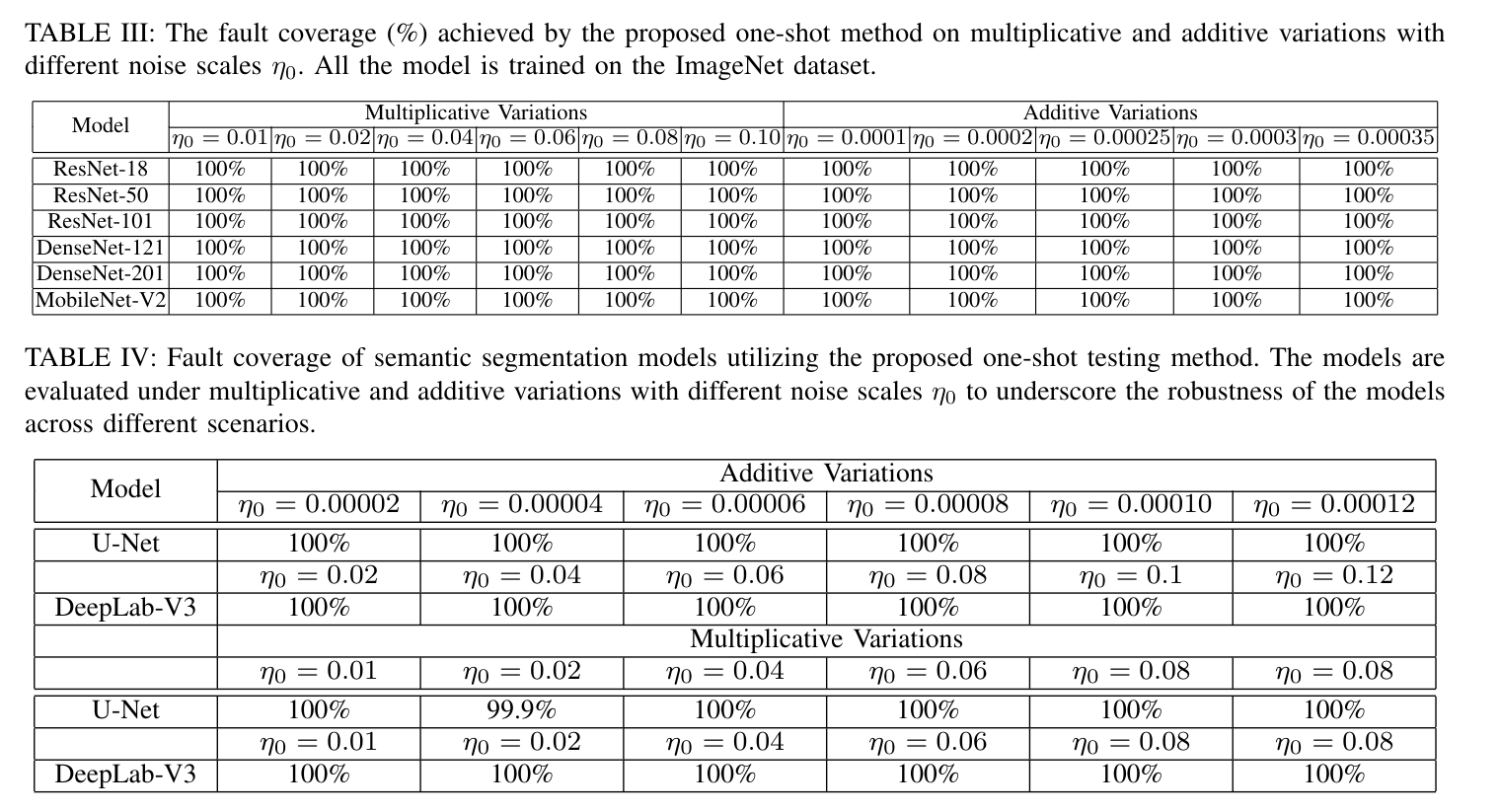
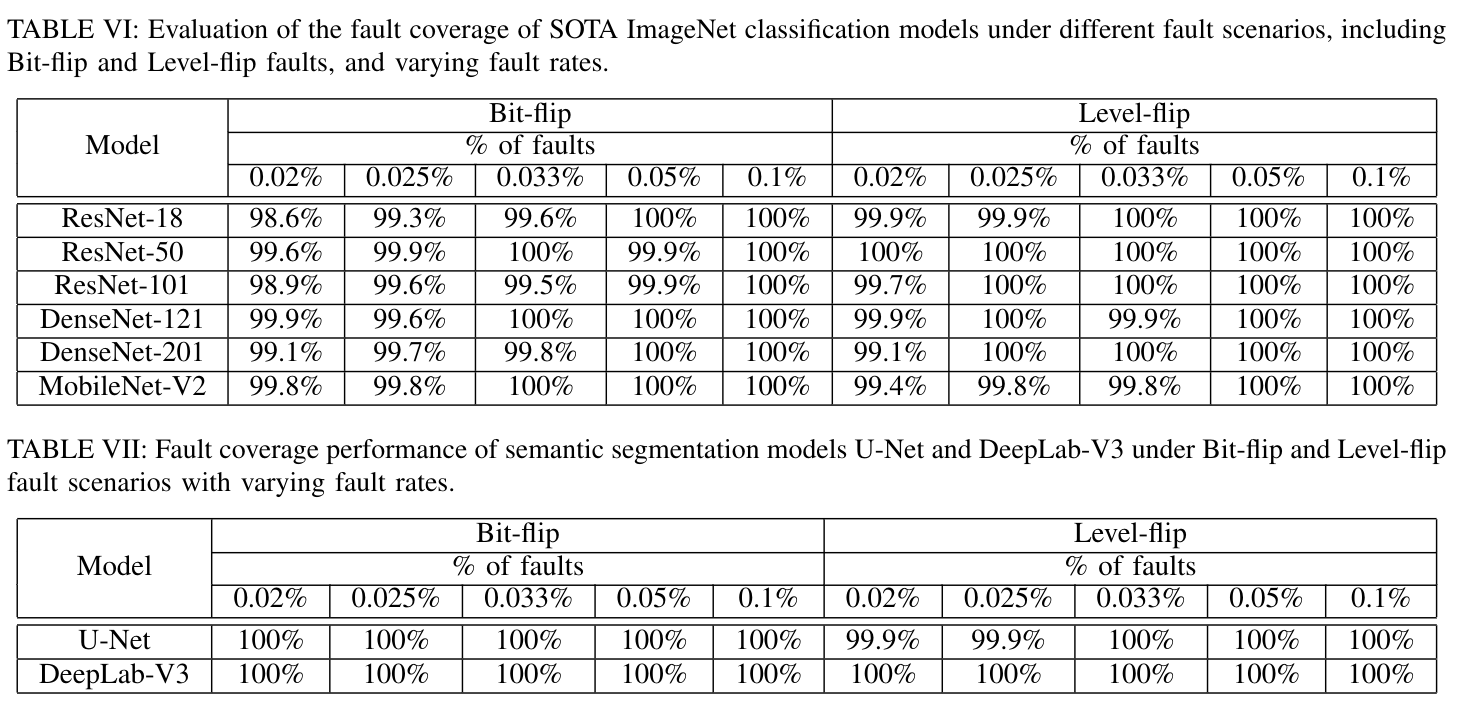
4. Results
They evaluate on large models:
- up to 201-layer CNNs
- ImageNet classification (1000 classes)
- semantic segmentation (medical + COCO datasets)
Main findings:
- ~100% fault coverage in most scenarios
- Works under:
- bit-flip faults
- level-flip faults
- additive/multiplicative noise
- Robust across models like:
- ResNet
- DenseNet
- MobileNet
- U-Net
- DeepLab
Stuff
- The problem and motivation that papers address
- NN accelerator testing
- What fault model is used
- noise
- bit flips
- Is it about detection, localization, or both?
- detection
- What method and metrics are used?
- fault coverage,
- What is one limitation or open question? (gap)
- mroe precise threath model
- localization
 reply via email
reply via email