REACT : SYNERGIZING REASONING AND ACTING IN LANGUAGE MODELS
April 4, 2024 | 700 words | 4min read
Paper Title: ReAct: Synergizing Reasoning and Acting in Language Models
Link to Paper: https://arxiv.org/abs/2210.03629
Date: 6. October 2022
Paper Type: LLM, LLM-Agent
Short Abstract:
They introduce the technique ReAct which allows LLMs to generate both reasoning and task-specific actions, by combining actions with language.
1. Introduction
One thing that makes out human intelligence is the ability of combining task-related action with verbal language reasoning. For example we might use language to keep track of our current progress. This forms a tight connection between “reasoning” and “acting”.
CoT is one example in which the authors tried to combine reasoning with actions, the problem with this approach is that it is a black-box, it uses its own internal state to generate thoughts and it is not grounded in the real world.
ReAct prompts LLMs to generate both verbal reasoning and action regarding a specific task, while incoperating external tools. They test this method on various datasets and find positive results.
This approach is similar to the Toolformer paper, they differ in that ReAct uses a few-shot setting meaning examples in the prompt to teach LLM on how to use the tools(in this paper called actions), while toolformer trains the LLM supervised on how to use tools.
2. ReAct: Synergizing Reasoning + Acting

We have a general Agent setup:
- Observations \( o_t \in O \)
- Actions \( a_t \in A\)
- Policy \( \pi(a_t \ | \ o_t)\) with context \( c_t = (o_1, a_1,...,o_{t-1}, a_{t-1}, o_{t})\)
The Idea of ReAct is now the following: we expand the agents action space \( A' = A \cup L \), where \(L\) is the space of language. We will call an action in \(a_{t}' \in L\) a thought, this does not effect the external environment. This thought consists of useful reasoning based on the current context \(c_t\) and is used to update the context \( c_{t+1} = (c_t, a_{t}') \). In Figure 1 we can see various thoughts e.g. (2b, Act1, Thought 1), (1d, Thought2, 4).
The language space \(L\) is unlimited they use the LLM PaLM with few-shot in context to generate actions and thoughts. For reasoning task, they alternate between generating thoughts and actions. For decision tasks, the LLM decides itself if to do an action or thought.
Example Snippet for ReAct:
Question Musician and satirist Allie Goertz wrote a song about the “The Simpsons” character Milhouse, who Matt Groening named after who?
Thought 1 The question simplifies to “The Simpsons” character Milhouse is named after who. I only need to search Milhouse and find who it is named after.
Action 1 Search[Milhouse]
Observation 1 Milhouse Mussolini Van Houten is a recurring character in the Fox animated television series The Simpsons voiced by Pamela Hayden and created by Matt Groening.
Thought 2 The paragraph does not tell who Milhouse is named after, maybe I can look up “named after”.
Action 2 Lookup[named after] Observation 2 (Result 1 / 1) Milhouse was named after U.S. president Richard Nixon, whose middle name was Milhous.
Thought 3 Milhouse was named after U.S. president Richard Nixon, so the answer is Richard Nixon.
Action 3 Finish[Richard Nixon
3. Knowledge Intensive Tasks
They consider two tasks:
- HotPotQa, questioning answering benchmark that requires reasoning of over two wikipedia passages.
- FEVER, a fact verification benchmark where wikipedia passages need to be found that support the claim or not.
The Action space consists of the following actions:
- \(search[entity]\), which returns the first 5 sentences from the corresponding wiki page.
- \(lookup[string]\), which returns the next sentence in the page containing the string.
- \(finish[answer]\), which finished the current task.
For ReAct prompting they select 3 to 6 random examples from the training set annotate them with thoughts, actions and transform them into the ReAct format
As baseline they compare:
- Standard prompting
- Chain-of-thought(CoT)
- Acting only prompting, which removes thoughts.
They observe that CoT suffers more from hallucination than ReAct.
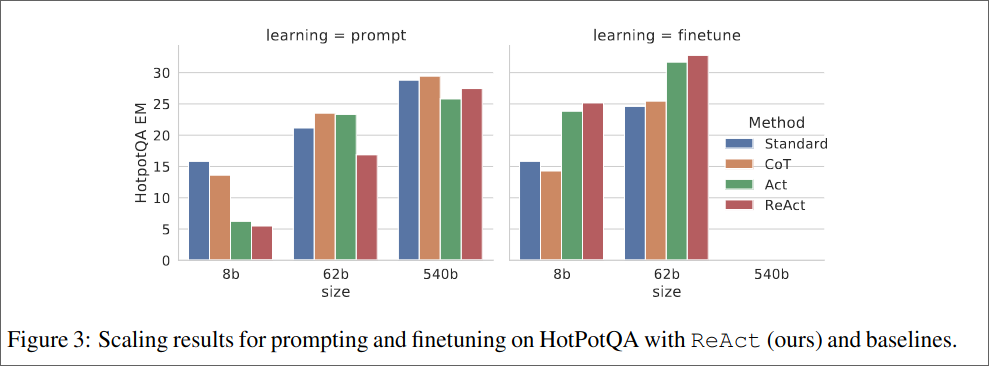
4. Decision Making Tasks
They considered two tasks
- ALFWorld, is a synthetic text-based game where the agent needs to fulfill certain goals.
- WebShop, a online shopping website where the agent needs to do an purchase.
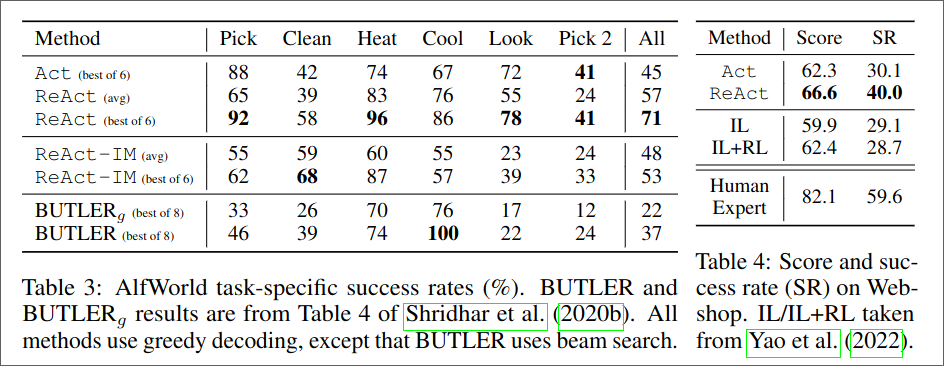
5. Conclusion
The authors proposed ReAct a framework which combines verbal reasoning with actions and achieves good results on tested benchmarks.
 reply via email
reply via email