Reflexion: Language Agents with Verbal Reinforcement Learning
February 4, 2024 | 645 words | 4min read
Paper Title: Reflexion: Language Agents with Verbal Reinforcement Learning
Link to Paper: https://arxiv.org/abs/2303.11366
Date: 20. March 2023
Paper Type: LLM, RL, Agent, prompting
Short Abstract:
LLMs have increasingly interacted with different environments (e.g., APIs, games). However, learning through Reinforcement Learning (RL) is not efficient because it requires many trial-and-error iterations. The author proposes a new technique called Reflexion, which seeks to remedy this.
1. Introduction
Recent papers have shown the effectiveness of using LLMs as decision-making agents in external environments. In these papers, LLMs generate text based on observations of the world. This generated text is then interpreted as an action of the agent and executed. The problem is that these LLM agents need to be trained, but using traditional RL would require too many trial-and-error iterations and a high amount of computational resources.
Reflexion uses verbal reinforcement to help the agent learn from its failures. For that, Reflexion converts a reward signal to verbal feedback for the agent, which the agent can then use to learn. This can be understood to be similar to how humans learn, in an iterative manner by reflecting on past mistakes.
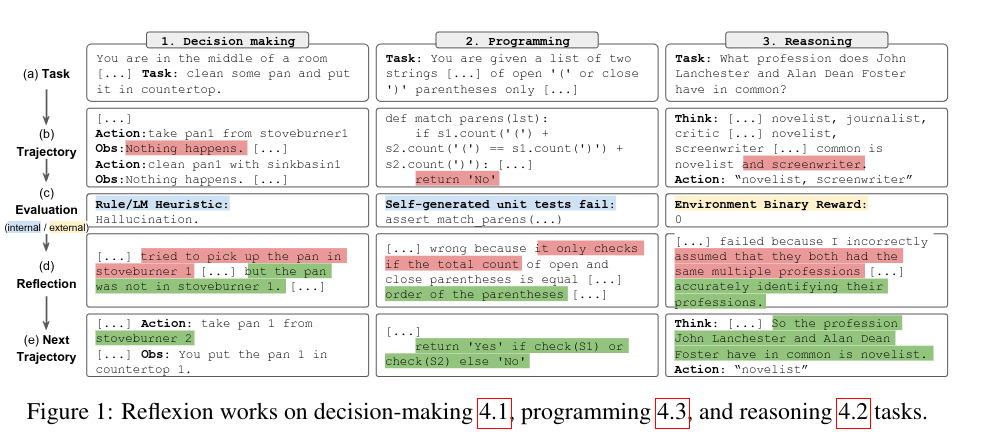
To generate this verbal feedback, the authors explore three ways:
- Simple Binary Enviroment Feedback
- Pre-Defined Heuristic
- Self-Evaluation using LLMs
Reflexion is not designed to achieve perfect accuracy; its goal instead is to demonstrate the ability to learn from trial and error.
2. Reflexion: reinforcement via verbal reflection
The Reflexion model consists of the following modules:
- an Actor $M_a$, which generates text and actions.
- an Evaluator $M_e$, that scored the output of the actor.
- and a Self-Reflection model $M_{sr}$, which generates verbal feedback.
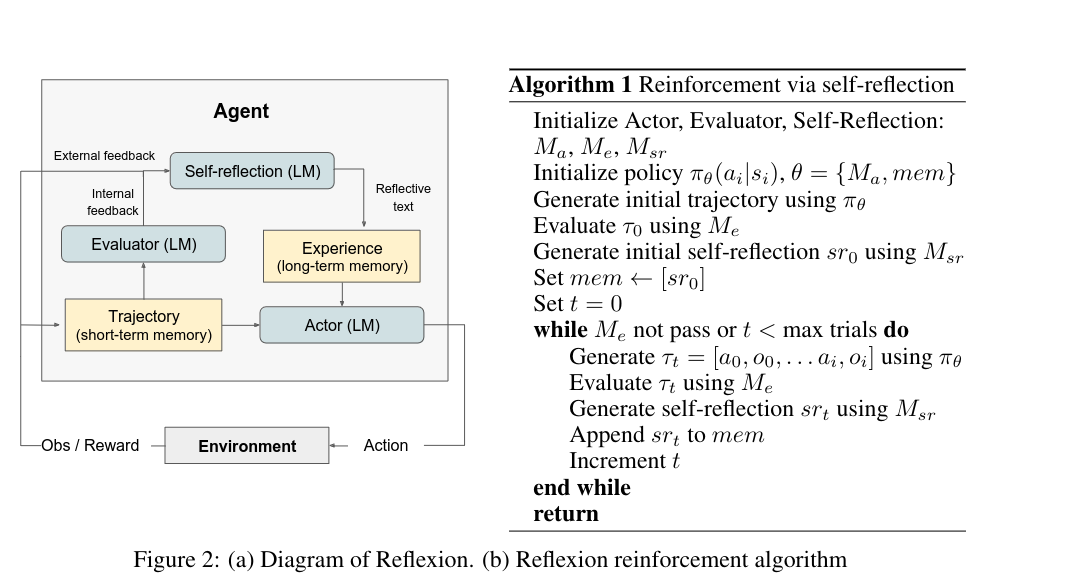
Actor The actor is built upon an LLM that is prompted to generate text and action conditioned on the observations of the environment and its memory. To generate text, they try different prompting techniques such as Chain-of-thought and ReAct. The memory component is used for in-context learning.
Evaluator The Evaluator takes as input the currently generated actions and computes a reward for them. The evaluator is task-specific; for reasoning tasks, rewards are based on an exact match, and for decision-making tasks, predefined heuristic functions are used. Additionally, they also tried using a different LLM as an evaluator.
Self-Reflection The Self-Reflection is based on an LLM and is used to generate verbal self-reflection feedback for future trials. It takes as input the reward generated by the evaluator, the current actions, and the memory, and outputs specific feedback based on that. This feedback is then stored in the memory.
Memory The authors differentiate between short-term and long-term memory; both are used by the actor model in inference. While training, the current actions serve as short-term memory, and the output of the self-reflection serves as long-term memory.
The Reflexion process At the first trial, the actor produces its current actions by interacting with the environment. The evaluator then gives a scalar score for the actions. After the first trial, the scalar score is analyzed by the Self-Reflection module and converted into verbal feedback. After each trial, the verbal feedback is appended to the memory, and this memory is bounded to the last 1-3 experiences.
3. Benchmarks
The authors evaluate their Reflexion model on the following tasks and datasets:
- Decision-making: AlfWorld
- Reasoning: HotPotQA
- Code-Generation: HumanEval, MBPP and LeetcodeHard.
3.1 Decision-making
AlfWorld is a text-based environment that challenges the agent to solve multiple-step tasks in an interactive environment.
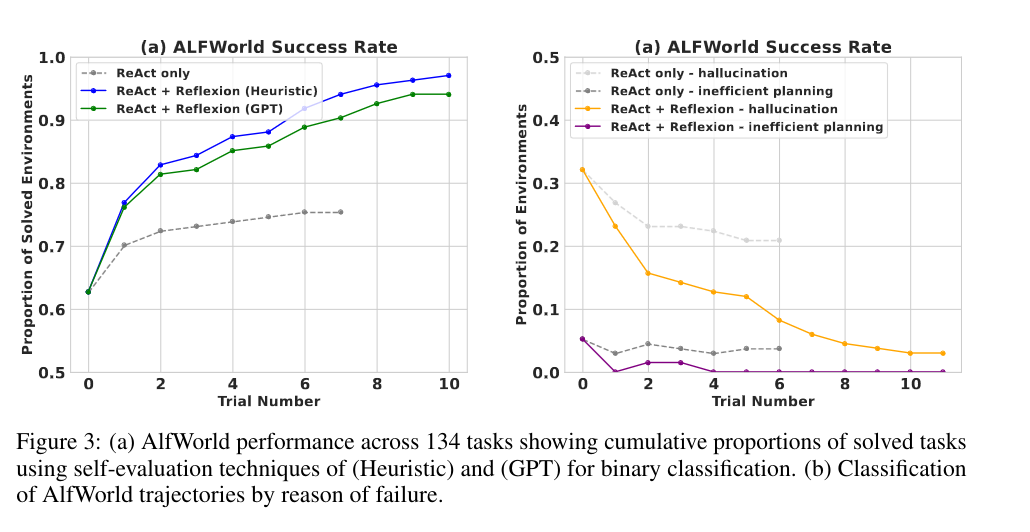
Using Reflexion significantly outperforms prior methods using LLMs.

3.2 Reasoning
HotPotQA is a Wikipedia-based dataset with question-and-answer pairs, where the agent needs to parse content over several documents to solve the questions.
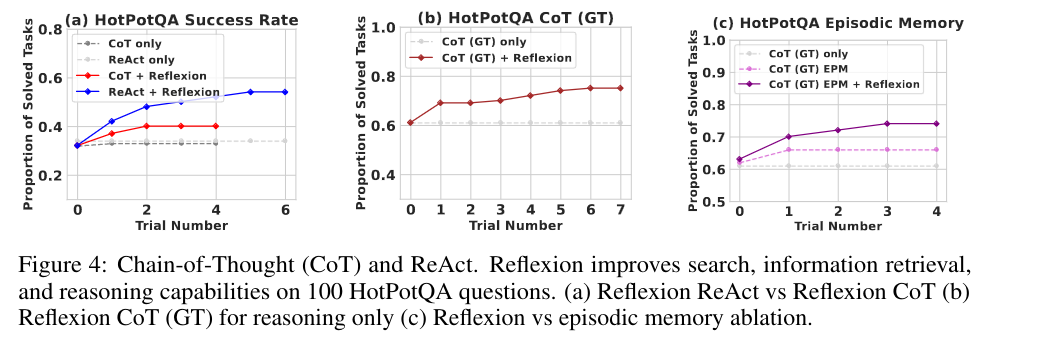
Reflexion outperforms all baseline approaches.
3.3 Code-Generation
HumanEval, MBPP, and LeetcodeHard are all code datasets where the agent is given a programming task that it needs to solve.

Reflexion outperforms all baseline accuracies.
5. Conclusion
Reflexion agents significantly outperform other decision-making agents. In addition, they can learn from their past mistakes.
 reply via email
reply via email