ReST meets ReAct: Self-Improvement for Multi-Step Reasoning LLM Agent
April 6, 2024 | 589 words | 3min read
Paper Title: REFINER: Reasoning Feedback on Intermediate Representations
Link to Paper: https://arxiv.org/abs/2312.10003
Date: 15. December 2023
Paper Type: LLM, LLM-Agent
Short Abstract:
This paper introduces an LLM-Agent using the ReAct framework combined with their new technique ReST which iteratively train using RL.
1. Introduction
For simple task such as question answering one can just ask the LLM and it works relative good, but for more complex tasks prompting directly isn’t good enough. Instead lately LLM-Agents have become very popular for this, which decompose the complex task into multiple smaller ones, often using external tools and APIs.
One popular example for LLM is the ReAct framework in which chain-of-thought is combined with actions and observations, for several action-observation rounds.
One question we can ask is “How can we improve the results of the model?”. The answer to that for directly prompting, is to train our model for longer by collecting more data. But this is expensive, instead the authors focus on self-critique and synthetic data generation. They use the ReST algorithm.
ReST works as follows: We have a outer loop, with which we grow our dataset by sampling from the latest policy. And we have a inner loop in which we improve our model, by using a reward model. In the paper, the authors use completion of a multi-trajectory for growing the dataset and do the improving by calling the LLM directly.
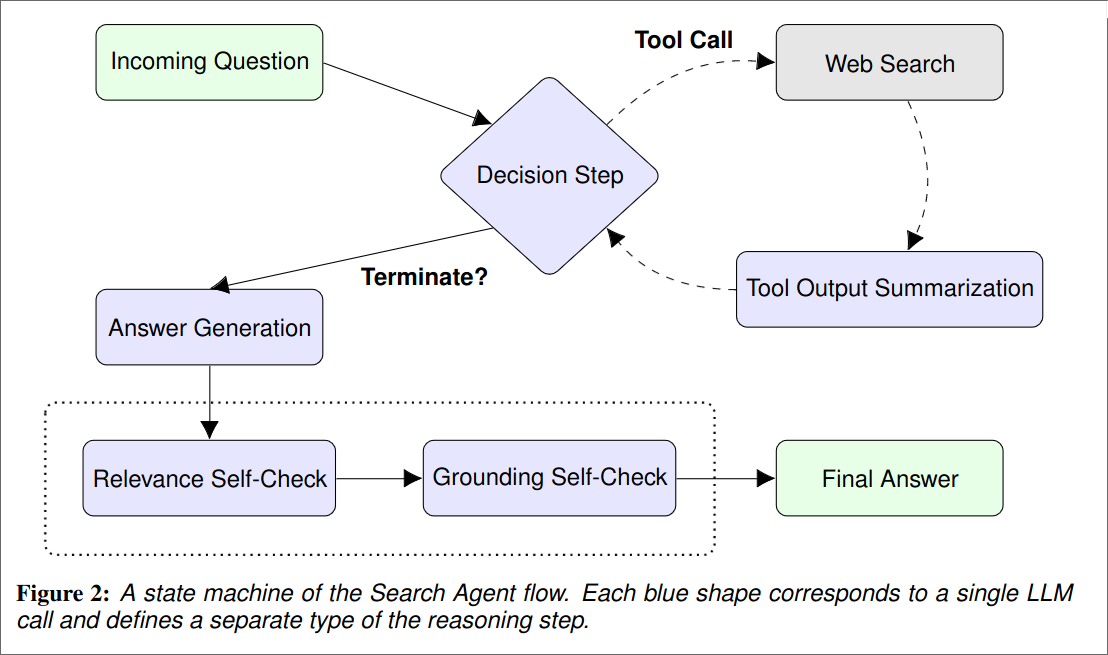
2. Background: Search Agent
Their Search Agent uses ReAct with Reflexion. In addition they use web-search as tool for generate answers. The agent works as follows:
- Agent receives a question
- Agent decides whether its needs more information to answer the question.
- If “yes”, calls the search tool, summarizes the received snipped and goes back to the decision step.
- If “no”, terminates search loop.
- Based on the collected information from the search loop, gnerated first answer attempt
- If then perform two self revisions to produce the final answer
- One to verify that the answer is relevant to the question
- One to verify that the answer is grounded in the retrieved snippets.
3. Method
3.1 Prompts
They first construct a few example for the search agent for each reasoning step for Figure 2. They format their prompt in code form because it makes it easier to integrate it with other systems.
3.2 Input Data
For the search agent trajectories they used following data:
- HotpotQA
- Eli5
- Eli5-askH
- Eli5-aslS
They used 500 random question from each of the datasets, so 2000 in total.
3.3 Fine Tuning
They split up each search agent trajectory into the reasoning steps and used them for fine tuning.
3.4 Ranking/Reward Model
They try different methods:
- Choose the trajectory that minimized the perplexity the most.
- They ask a PaLM 2-L model to rank the different samples, by providing the different samples, the input and guidance on how to rank them.
3.5 Iterative Self-Improvement
The Algorithm works now as follows:
- Start with a LLM capable of performing as Search Agent. Collect reasoning trajectories from this model based on the 2000 initial selected questions.
- Convert the trajectories into fine-tuning dataset. Apply re-ranking with the Reward Model.
- Fine-tune the new model on this dataset. Repeat the process.
4. Evaluation
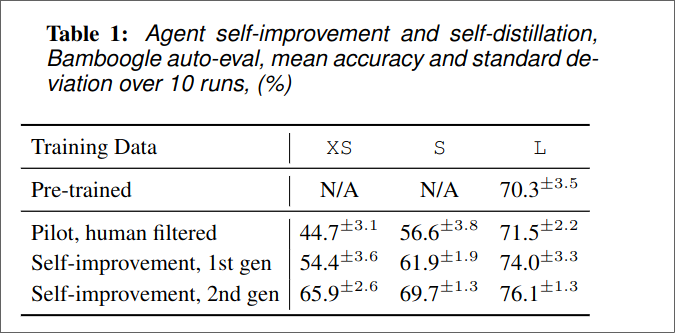
For evaluation they use the Bamboogle dataset, which requires 2 hops to answer.Because Bamboogle is a relative small dataset they introduce BamTwoogle dataseton which they test, to guard against over fitting.
5. Conclusion
Noteworthy is:
- They don’t use labels from the trainings data for the projection collection.
- The Model can learn something useful, even from states that lead to the wrong answer.
 reply via email
reply via email