Runtime Fault Localization in Deep Neural Network Accelerators
May 11, 2026 | 991 words | 5min read
Paper Title: Runtime Fault Localization in Deep Neural Network Accelerators
Link to Paper: https://dl.acm.org/doi/10.1145/3770920
Date: 11. Nov 2025
Paper Type: Systolic arrays, deep neural network (DNN) accelerator, fault detection, fault localization, Checksums
Short Abstract: Systolic arrays are widely used for accelerating deep neural networks (DNNs) due to their high parallelism and data reuse efficiency. However, hardware faults in their numerous processing elements (PEs) can propagate errors and significantly degrade inference accuracy. The paper addresses the open challenge of fault localization in systolic arrays. It proposes a lightweight fault tolerance framework that performs both run-time fault detection and localization during normal operation. The approach uses functional data to generate checksums on-the-fly, eliminating the need for dedicated test patterns or system downtime. Reuslts: 100% fault detection and localization, 2% Area overhead.
1. Introduction
Deep Neural Networks (DNNs) are computationally intensive, driving the development of specialized hardware accelerators, such as Google’s Tensor Processing Unit (TPU), which relies on systolic arrays. Systolic arrays consist of a grid of Processing Elements (PEs) that perform multiply-and-accumulate (MAC) operations with efficient dataflow and high parallelism.
However, systolic arrays are vulnerable to hardware faults. Due to their dataflow nature, an error in a single faulty PE can propagate downstream, significantly degrading DNN inference accuracy.
Key Limitations of Existing Approaches:
- Algorithm-Based Fault Tolerance (ABFT) mainly detects input data errors, not hardware faults in the accelerator.
- Scan-based and manufacturing tests often miss runtime, aging, or environmental faults.
- Hardware redundancy methods (spare PEs) assume fault locations are already known, leading to poor localization and excessive bypassing of healthy PEs.
- Software-based solutions (e.g., dropout) are limited and require prior knowledge of fault locations.
Proposed Solution: The paper introduces a runtime fault tolerance framework for systolic arrays that addresses both fault detection and precise fault localization during normal operation:
- Uses functional data to generate checksums on-the-fly (no dedicated test patterns or downtime needed).
- Achieves 100% fault detection coverage.
- Can localize multiple concurrent faulty PEs.
- Enables dynamic reconfiguration using spare PEs and a control hub.
2. Background
Deep Neural Networks (DNNs) consist of layers of neurons performing massive multiply-and-accumulate (MAC) operations. Systolic arrays accelerate these workloads through a grid of Processing Elements (PEs) with efficient data reuse and parallelism.
The paper focuses on the Weight Stationary (WS) dataflow:
- Weights are pre-loaded and stationary in columns.
- Input features flow from left to right.
- Partial sums flow downward and accumulate along columns.
- This process repeats for different weight matrices.
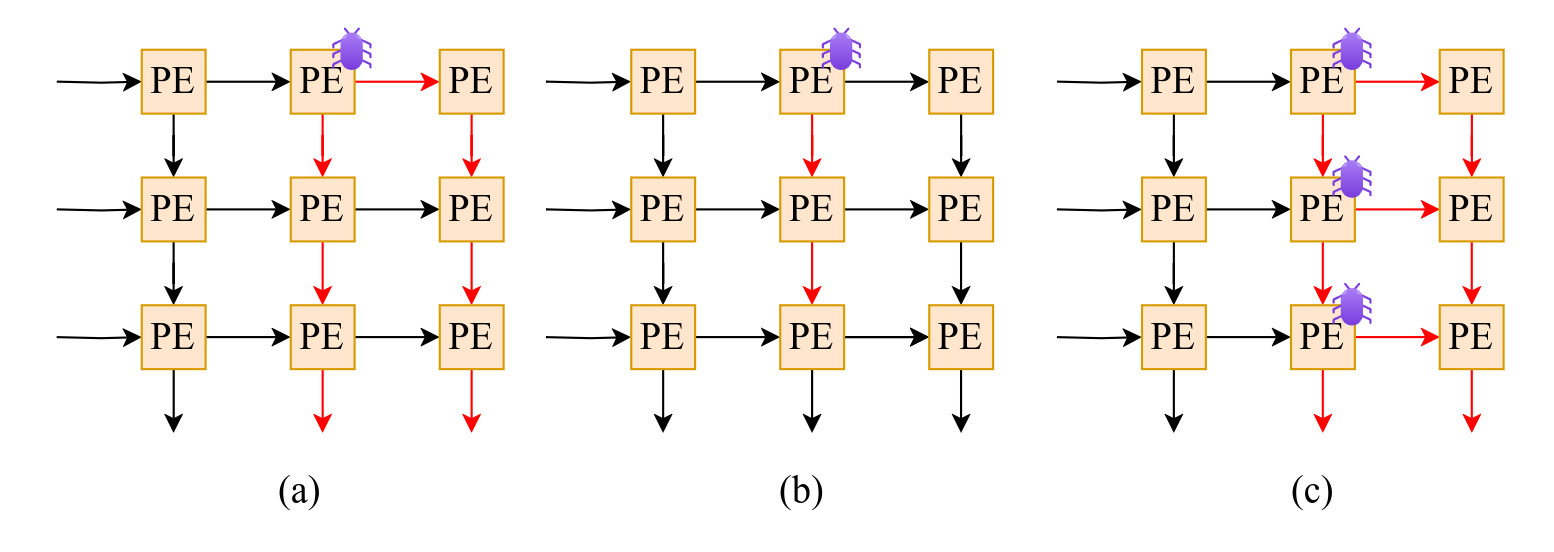
A single faulty PE can cause significant accuracy degradation in DNN inference because errors propagate through the array due to the interconnected dataflow.
Fault Propagation in WS Dataflow:
- Faults in weight registers, partial sum registers, or MAC unit → errors propagate column-wise (down the column).
- Faults in input registers → errors propagate both row-wise and column-wise (affecting many downstream PEs).
Faults in the same PEs are reused across different layers, repeatedly corrupting outputs and severely hurting overall model accuracy.
3. Related Work
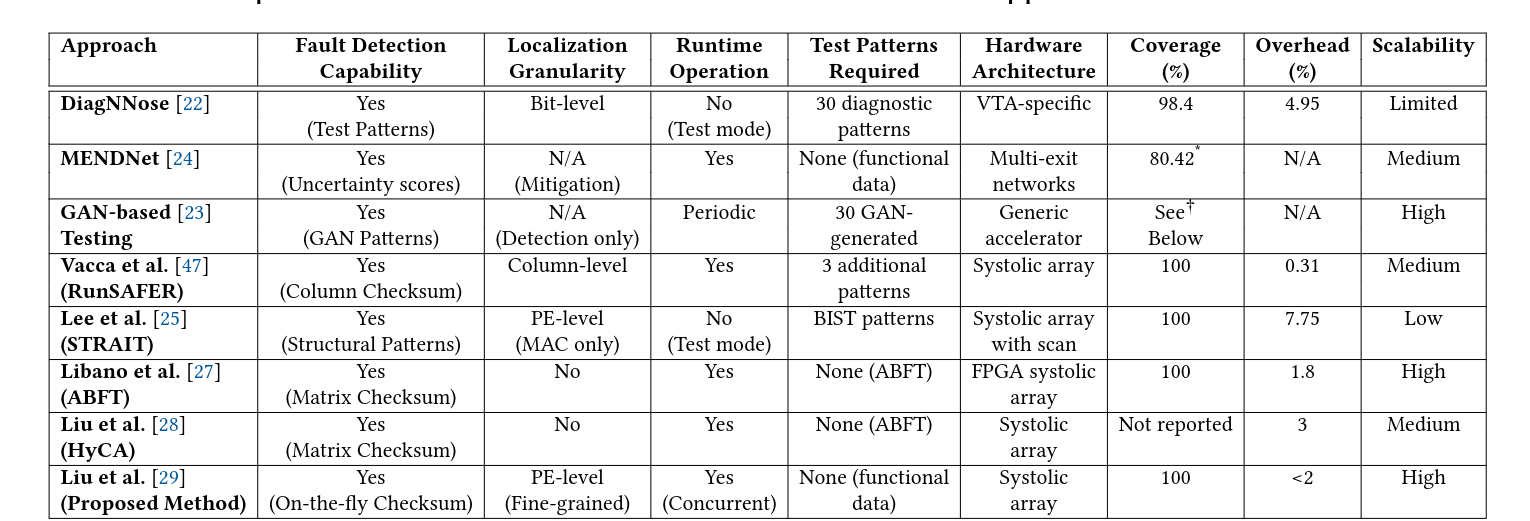
4. Methodology: Proposed Fault Localization Framework
4.1 Fault Model
The method covers faults that affect PE computation results, including:
- Stuck-at faults in the MAC unit
- Faults in weight, input, and partial sum registers
- Interconnection faults (opens, shorts, bit flips), which can be modeled as register faults
Designed for Integer operation, but can be extended to floating-point.
4.2 Fault Detection
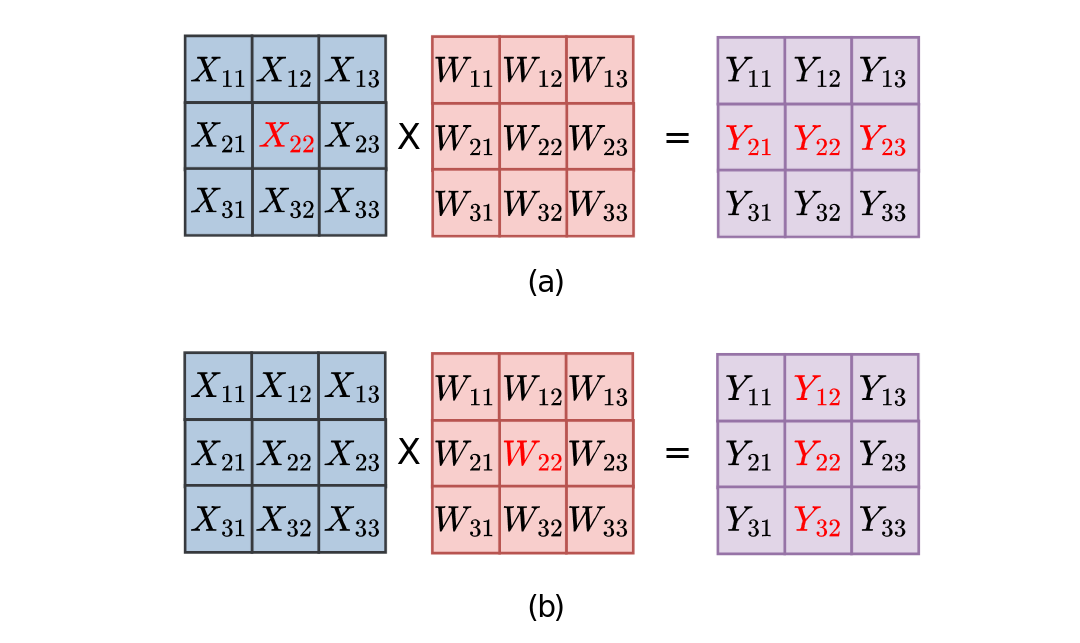
Instead of dedicated test patterns, the method leverages functional data during normal matrix multiplication (X × W = Y) to generate golden checksums on-the-fly.
For each column j of the systolic array, they compute a column checksum CSⱼ, which is the sum of all outputs (partial sums) from that column. Using the mathematical property of matrix multiplication:
CSⱼ = Σᵢ Yᵢⱼ = Σₖ Wₖⱼ × (Σᵢ Xᵢₖ)
This allows efficient verification of column integrity.
Implementation:
- A small additional 1 × N spare PE array is used to compute the required row sums of the input matrix and generate the checksums.
- Checksum computation runs concurrently with normal systolic array operation.
- The checksum for each column is produced with only one-cycle latency relative to the final output of that column.
Detection Capability:
- Any fault in a PE (stuck-at, bit flips, register faults, etc.) that alters the output causes a mismatch between the observed column sum and the computed checksum → error detected.
- Faults are only detected when the faulty PEs are activated by the incoming data/weights. Inactive faults may remain latent until triggered.
- The method works with regular functional inputs and requires no extra computation on the original data.
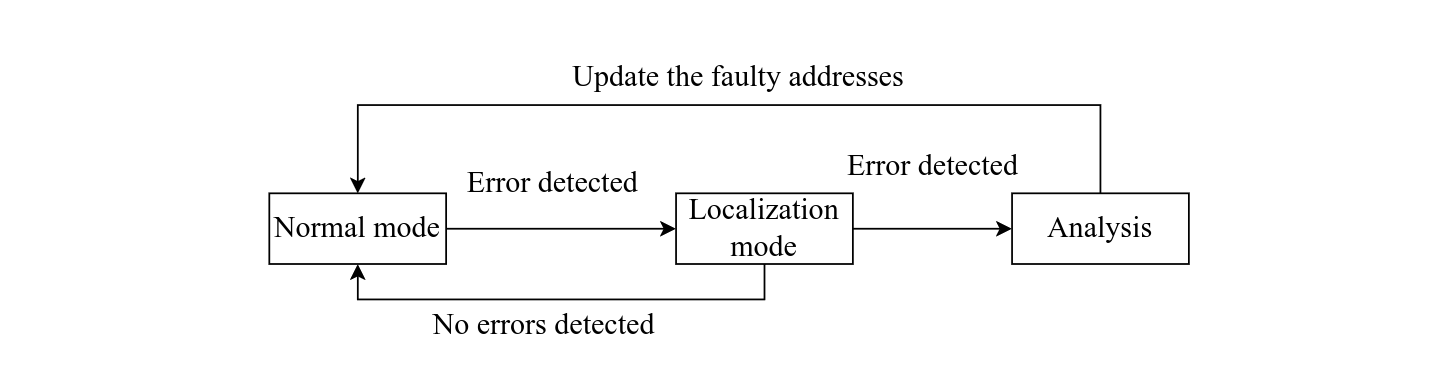
4.3 Fault Localization
When a checksum mismatch is detected during normal operation, the system switches to a dedicated fault localization mode.
Every PE is equipped with its own error checker that monitors its partial sum output. This is used for localization.
4.4 Proposed Hardware
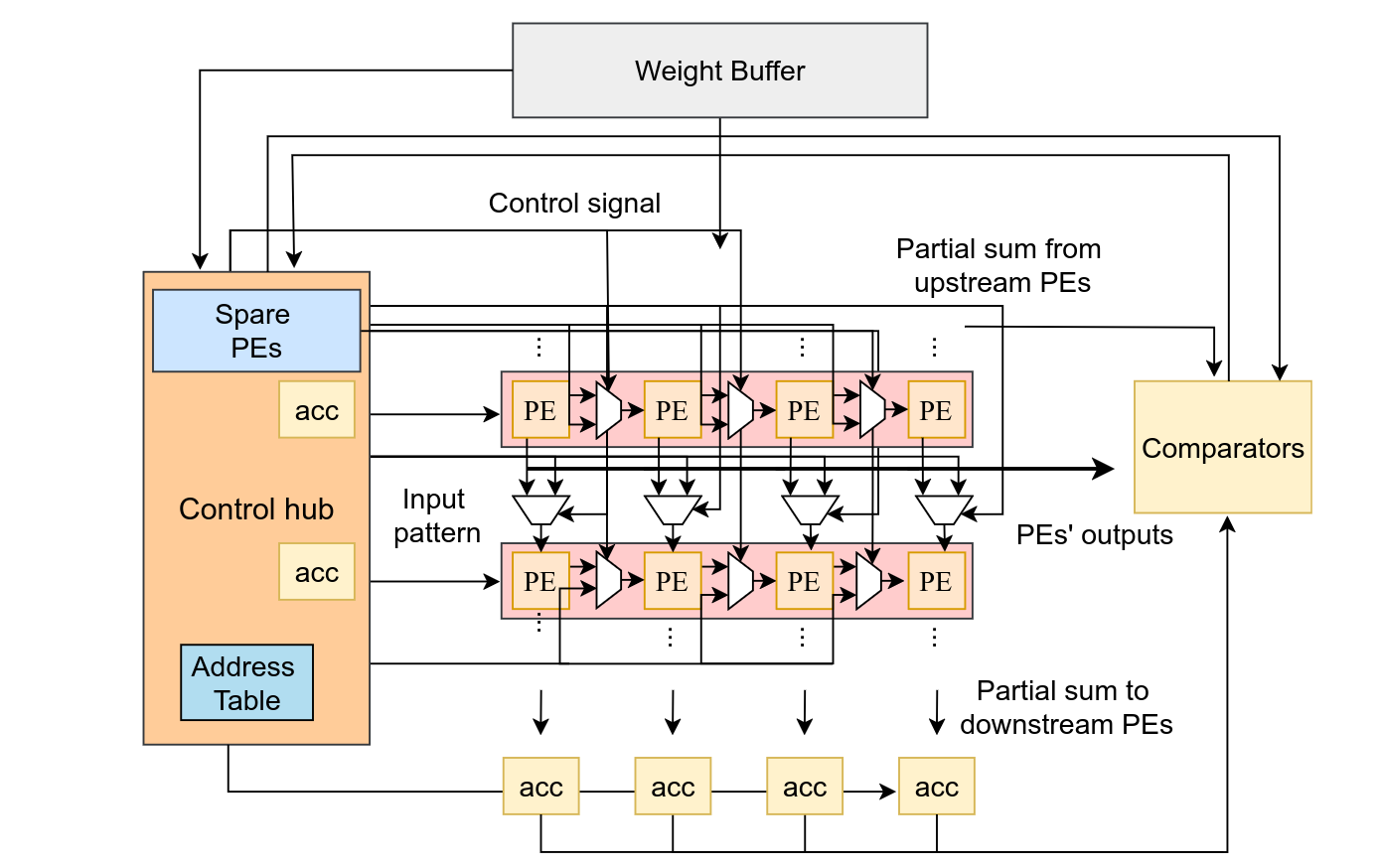
5. Results
Results:
- 100% Test Coverage
- 2% Area Overhead
- 1 Additional Test Cycle
- ~100% Correct Fault Localization
Some Thoughts
- Accelerators need to be designed with this in mind i.e. works only on Hardware specifically designed with this in mind.
- The problem and motivation that papers address
- Faults in Accelerators for DNN
- What fault model is used
- Stuck-at-faults, bit flips, calualiton errors
- Is it about detection, localization, or both?
- Both
- What method and metrics are used?
- Test Coverage, Area Increase, Additional Computation Overhead
- What is one limitation or open question? (gap)
- Only works on Accs designed with this in mind
- Doesnt work on desktop pc, everyday devices
 reply via email
reply via email