Self-Instruct: Aligning Language Models with Self-Generated Instructions
February 2, 2024 | 630 words | 3min read
Paper Title: Self-Instruct: Aligning Language Models with Self-Generated Instructions
Link to Paper: https://arxiv.org/abs/2212.10560
Date: 20. December 2022
Paper Type: LLM, Alignment, Instruction
Short Abstract:
Language Models (LLM) that are “instruction tuned” have demonstrated excellent raw performance and adherence to instructions. However, instruction tuning typically requires substantial amounts of human-labeled data. This paper introduces Self-Instruct, a technique for instruction tuning a LLM without relying extensively on human-labeled data.
1. Introduction
Recent advancements in Language Models (LLM) have significantly enhanced their performance, attributed to the use of pre-trained LLM and subsequent fine-tuning (as seen in the InstructGPT paper) on human-written instructional data (e.g., SUPER-NATURALINSTRUCTIONS). The challenge lies in the impracticality of collecting large datasets, often lacking diversity in the provided instructions.
In this paper, the authors propose SELF-INSTRUCT, a semi-automated process for instruction fine-tuning of LLM using instructions generated by the language model itself. The process begins with a small set of human-written tasks, which are then used iteratively to generate new task instances.
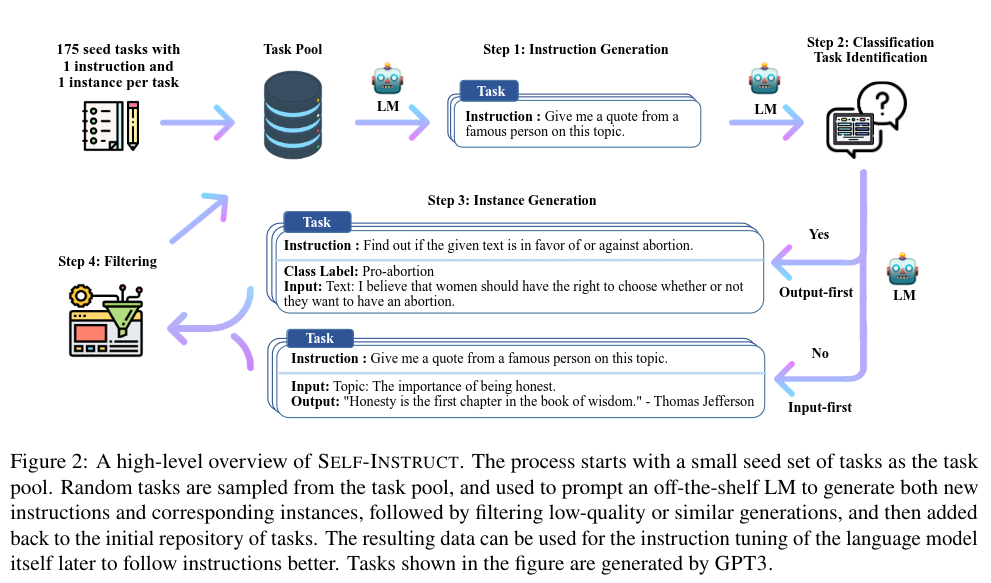
In the Self-Instruct algorithm, the model is prompted to generate instructions for new tasks by leveraging the existing collection of instructions. Additionally, it is prompted to generate new instances (i.e., new examples) for a task. Subsequently, the generated content is filtered and added to the task pool.
To evaluate Self-Instruct, GPT-3 is employed and fine-tuned on the newly created data, followed by a comparison with other popular models. The authors also utilize ROUGE-L testing to assess the overlap between seed data and newly generated data, revealing only a small overlap.
2. Method
2.1 Instruction Data
Instruction data defines a task in natural language, each with an input-output instance associated. A model is expected to produce the output when given the instance and the input.

2.2 Automatic Instruction Data Generation
Their pipeline for generating new data consists of four steps:
- Instruction Generation
- Identifying the type of the generated tasks
- Generating instances for the tasks
- Filtering low quality data
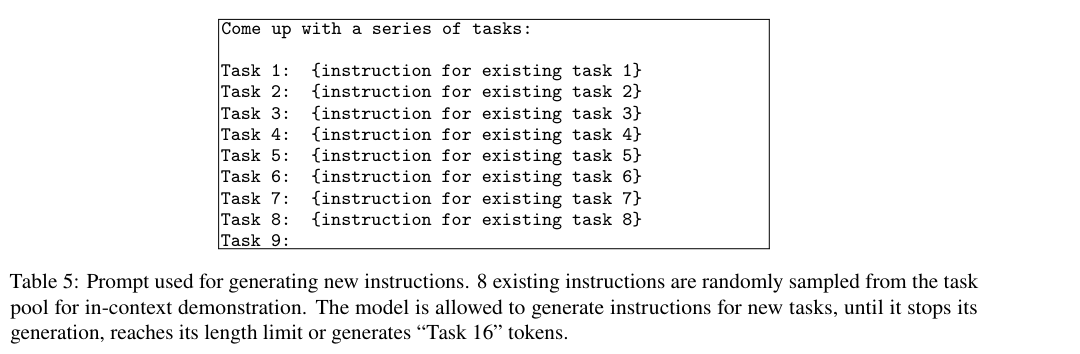
Instruction Generation Initially, the task pool contains a small number of tasks, each with one instance. At each step, a number of tasks are sampled from this pool, including both human-written and generated tasks. The following prompt is used to generate new tasks:
Classification Task Identification To classify the type of generated instruction, the LLM is prompted to determine whether a task is a classification task or not.

Instance Generation Given the instruction and task type, the LLM is asked to generate new instances, which can be done via the input-first or output-first approach.

Filtering and Postprocessing Filtering is performed using ROUGE-L, measuring the similarity between newly created text and existing content. If the content is too similar, it is discarded.
2.3 Finetuning the LLM
After generating the dataset using the Self-Instruct algorithm, the LLM can be fine-tuned on it. The model receives the input of the current instance and is asked to produce the corresponding output. Weights are adjusted based on the loss.
3. Produced Data
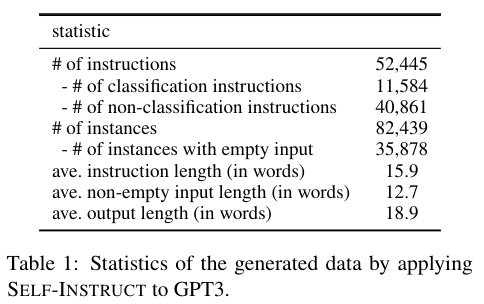
This section provides an overview of the dataset produced using GPT-3 and self-instruct.
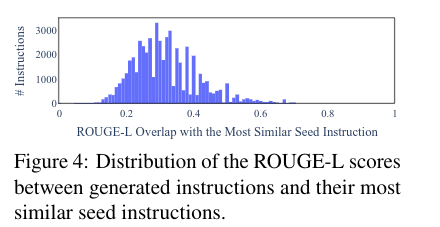
For each generated instruction, the authors measure the ROUGE-L overlap with the initial seed instructions, indicating minimal overlap.
To assess the quality of the data, samples are drawn from the dataset, and human evaluators are employed. Most generated tasks are found to be correct, and their instances are in the correct form. However, instances tend to have more noise than the generated tasks.
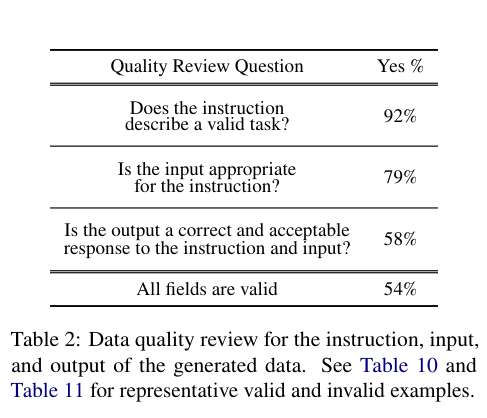
4. Results
For evaluation, the authors compare their tuned GPT-3 model with Self-Instruct against InstructGPT.
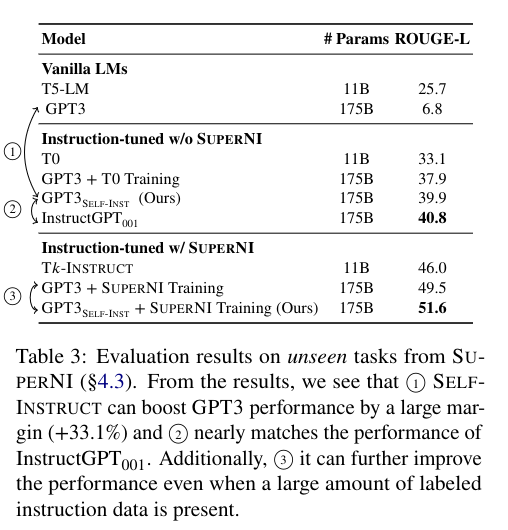
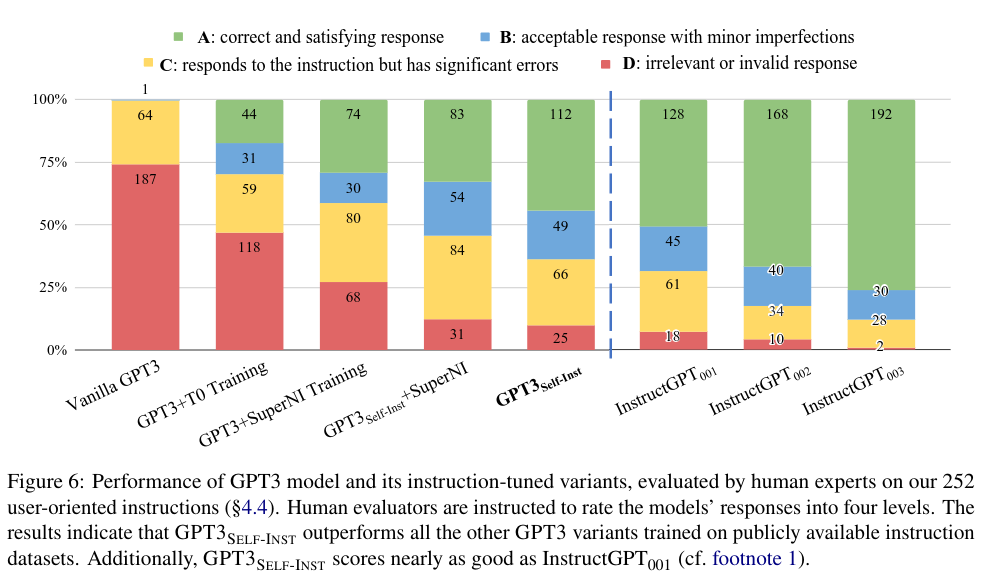
5. Conclusion
Self-Instruct facilitates significant performance gains for LLM even with limited initial data. Additionally, it proves to be nearly as effective as InstructGPT, which relies on a more extensive human-written dataset. Self-Instruct appears to be an accessible and cost-effective means to enhance the performance of any LLM, whether previously fine-tuned or not.
 reply via email
reply via email