Siren’s Song in the AI Ocean:A Survey on Hallucination in Large Language Models
April 2, 2024 | 1,377 words | 7min read
Paper Title: Siren’s Song in the AI Ocean: A Survey on Hallucination in Large Language Models
Link to Paper: https://arxiv.org/abs/2309.01219
Date: 3. September 2023
Paper Type: LLM, Hallucination
Short Abstract:
LLM’s often exhibit so called “Hallucination”, this paper gives an overview of the different types of Hallucination and mitigation techniques.
1. Introduction
It has been observed that LLM’s often times produce outputs that while plausible, conflict with the user input, with previous context, or with factual knowledge. This behavior is commonly called Hallucination, and hinder the reliability of the LLM. Analyzing the problem id made difficult by:
- Massive Trainings data: Makes it difficult to remove biased information
- Versatility of LLMs: LLMs are very general, making it hard to detect Hallucination.
- Generality of LLMs: Plausible output may be hallucinated.
In addition the black-box nature of finetuning and RLHF makes mitigation of Hallucination hard.
The Paper is split up in the following sections:
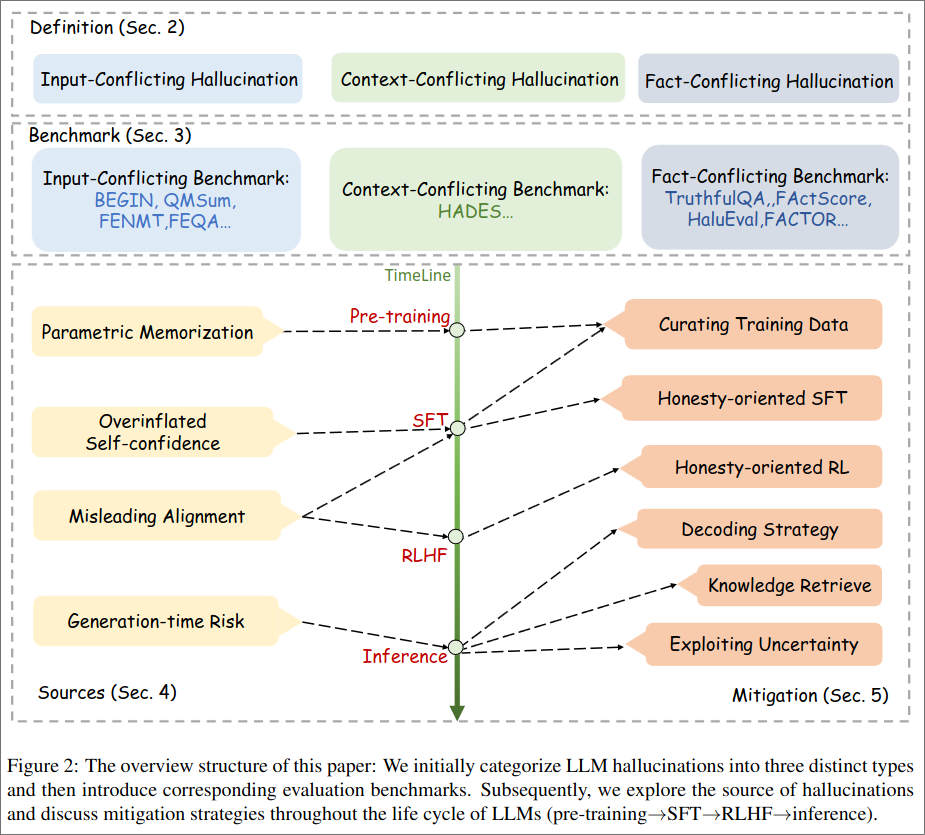
2. Definition
2.1 Large Language Models
Before the Transformation Architecture was leading Architecture of LLMs, recurrent neural networks and n-grams models were used. With a shift towards transformers models have become more general purpose, for that models are self-supervised pretrained on large amount of unlabeled data and then finetuned with labeled data on specific tasks.
It has been found that scaling up LLMs, both in terms of parameters and data, enables in context-learning, reasoning and instruction following.
2.2 What is LLM Hallucination
One of the biggest issue plaguing LLMs are Hallucination, which can be categorized into:
- Input-conflicting hallucination, LLMs output deviates from the user input.
- Context-conflicting hallucination, LLMs output conflicts with previously generated output.
- Fact-conflicting hallucination, LLMs output contain falsehoods.
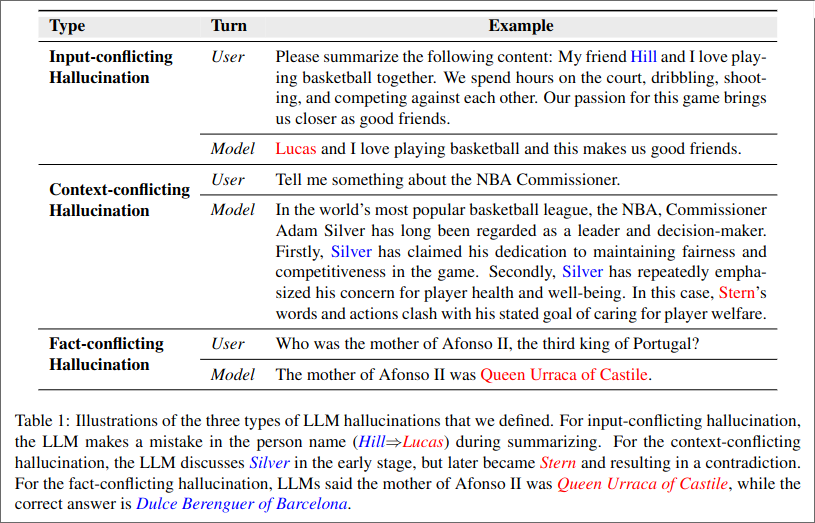
Most of the research focus of hallucination today was into fact-conflicting hallucination, this is due that input- and Context-conflicting hallucination are historical better studied in NLG settings. Fact-conflicting hallucination are hard because there is no central knowledge source.
2.3 Unique Challenges of LLMs
Massive Data
Much of the unlabeled data with which LLMs are trained is collected from the web which often contain fabricated or outdated data.
Versatility of Data
LLMs are often done in a multi-domain setting with free forming text, this makes evaluation through automated testing hard.
Invisibility of errors
LLMs may produce text that sounds plausible but has errors in it, which makes detecting errors hard.
3. Evaluation of LLM Hallucination
Evaluation of hallucination because of the free form nature of LLMs is much harder than for NLG tasks.
3.1 Evaluation Benchmarks
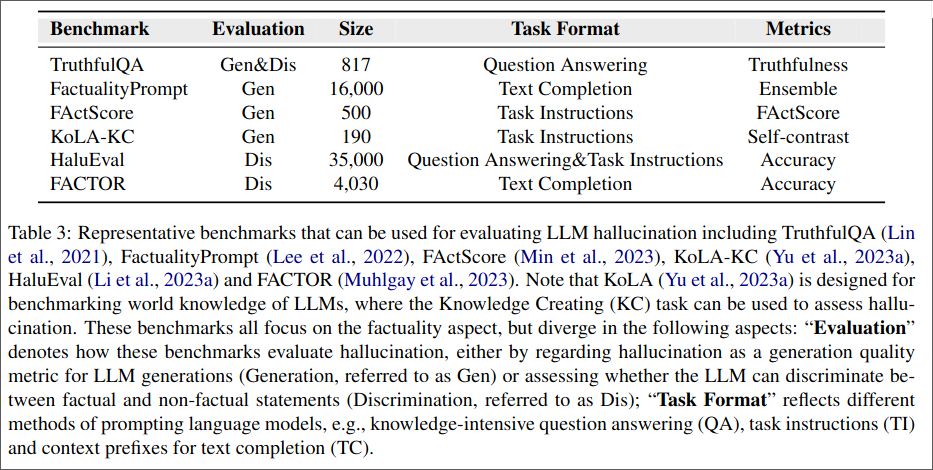
Evaluation Format We mostly differentiate between generating statements and discriminating statements(See example below). In Generation benchmarks we evaluate hallucination similar to coherency or fluency. In Discrimination benchmarks, we evaluate if a LLM can differentiate between a true and a hallucinated statement.

Task Format Some benchmarks use questioning-answers pairs, where the LLM is presented with a question and it needs to pick a already formulated answer. Other use task-instructions, where the LLM needs to generate responses and the factuality of these responses is evaluated. At last in task-completions, LLMs need to complete a text.
Construction Methods Most benchmarks use annotated human data. TrutthfulQA design questions to elicit false statements with a high likelihood. FActScore uses a pipeline toto transform generated output in atomic statements which can be evaluated. FACTOR uses an external LLM to generate non-factual statements and then use human to annotate them.
3.2 Evaluation Metrics
Human Evaluation
TrutthfulQA and FactScore require humans for evaluation, this ensures precision. Human evaluation has the problem of being subjective and expensive.
Model-based automatic evaluation
Several papers have used LLMs such at GPT to approximate human evaluations.
Rule-based automatic evaluation For discrimination tasks, rule based metrics such as accuracy can be used.
4. Sources of LLM Hallucination
LLMs Lack Knowledge
In pretraining LLMs obtain knowledge that is then stored in the parameters of the model. If during their training the LLM didn’t see a fact and it get asked about it, it may hallucinate. In addition LLMs are prone to amplify errors made in the dataset.
LLMs overestimate their capabilities
Experiment have shown that LLMs can asses their own reponses on truthfulness. But for LLMs it seems that they are as confident about incorrect results as correct results.
Problematic Alignment
After a tranformer is pretraiend and finetuned it is typically aligned through processes such as RLHF, but when LLM are trained on instruction finetuning on instruction for which their knowledge is not adequate. it will result in misalignment, which leads to hallucination.
Generation Strategy of LLM
LLMs generate token for token, this often leads to snowballing of ealier errors, instead of correcting them.
5. Mitigation of LLM Hallucination
5.1 Mitigation during Pretraining
Most of the knowledge of a LLM comes through its pretraining, noisy data i.e. Misinformation in the data corpus could corrupt the parameter of the model which will lead to hallucination.
From that follows, one approach to mitigate hallucination is the removal of noise from the data corpus, this mean manually elimination Missinformation and outdated information. It has been shown, that this reduces hallucination.
But this method is problematic due the sheer size of modern trainings datasets.
Therefore an automatic approach is needed, one example is GPT-3 which uses various cleaning methods to remove noise from their dataset.
Another approach is to only use data, from reputable sources e.g. wikipedia, arxiv ect.
5.2 Mitigation during SFT
During supervised fine-tuning(SFT) a LLM gets trained on a small labeled dataset to elicit certain behavior from the model e.g. instruction-fine tuning, removing bias and toxicity, being more helpful.
LLMs learn through behavior cloning on how to interact with the users.
SFT can increase the production of hallucination, by being to positive and confident. To mitigate it, it is important to built in honesty in the dataset i.e. model responds with “I don’t know”(See: constitution AI).
5.3 Mitigation during RLHF
After a model is finetuned often times RLHF is used to further improve the model. RLHF consists of two steps 1) training a reward model 2) use that reward model to train the LLM using RL.
Here it is important how the reward model is trained, it should respect the three H:
- Honesty
- Helpful
- Harmless Where honest refers to minimizing the number of hallucination. To do this synthetic hallucination data can be used to train the reward model.
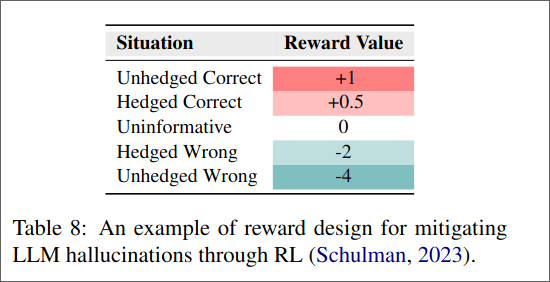
Another technique to mitigate hallucination proposed by Schulman is for the model to “hedge” its answers and based if it correct or not getting a reward.
5.4 Mitigating during Inference
5.4.1 Decoding Strategies
Decoding strategies can have a influence on hallucinations. So is nucleus sampling(top-p sampling) less factual than greedy decoding, this is due the randomness of nucleus sampling. A better sampling technique is factual-nucleus sampling. Other techniques which might help are:
- Chain-of-Verification, which uses plans and verification questions.
- Inference-Time Intervention, which puts a classifier on top of attention heads.
- context-aware decoding(CAD), uses contrasting ensembles for the LLM to pay more attention to the context instead of its parameters.
5.4.2 External Knowledge
Another solution is to use a external Ressource for providing facts, this is mostly done in two steps 1) identifying the relevant information and retrieving it 2) Using this information in the response.
Knowledge acquisition
To acquire up-to-date information from credible resources we can use one of these two methods:
- External knowledge bases: An example for this would be Wikipedia or even the entire internet.
- External tools: Examples would include calculator, date app, weather app, ect.
Knowledge Utilization After we have acquired the relevant information, we need to utilize it somehow:
- Generation Time Supplement: This would mean we concatenate them with the user input
- Post hoc correction: Using an auxiliary fixer after the response was generated.
5.4.3 Uncertainty of LLMs
Displaying the uncertainty a model has can provide the user valuable feedback on how much they should trust the model. Uncertainty of the model can be estimated with:
- Logit-based estimation, calculating the token-level probability.
- Verbal-based estimation, directly asking the llm to express their uncertainty.
- Consistency-based estimation.
5.5 Other Methods
Some other methods include:
- Multi agent interaction, multiple LLM propose and debate their responses.
- Prompt engineering, using “smart” prompts.
- Analyzing LLMs internal states, LLMs may be aware of their own falsehood use this.
- Human in the loop.
6. Conclusion
LLMs have achieved huge success, but its important to keep hallucination in mind and doing steps to mitigate them.
 reply via email
reply via email