SpikeGPT: Generative Pre-trained Language Model with Spiking Neural Networks
June 25, 2025 | 1,486 words | 7min read
Paper Title: SpikeGPT: Generative Pre-trained Language Model with Spiking Neural Networks
Link to Paper: https://arxiv.org/abs/2302.13939
Date: 27. Feb. 2023
Paper Type: LLM, SNN, Neuromorphic-Computing
Short Abstract:
This paper presents an LLM using the SNN architecture. To achieve this, the authors develop their own attention mechanism
1. Introduction
As the scale of LLMs continues to grow, they require increasingly more power, making them more costly to train. Spike-based neural networks (SNNs), especially when paired with neuromorphic hardware, hold great promise for significantly reducing power consumption in AI. In addition, they can be effectively incorporated into deep learning pipelines, granting access to state-of-the-art training techniques.
Until now, SNNs have not been deeply explored in the domain of NLP, unlike in other areas such as computer vision, where they have achieved competitive performance. This gap can be attributed to several challenges:
- Absence of effective language encoding techniques for SNNs
- Difficulty of training large SNNs due to:
- The vanishing gradient problem, which prevents long dependencies from being recalled
- The reliance on spiking behavior during training
- The non-differentiability of SNN operations
- Constraints imposed by binarized spikes
- Incompatibility of SNNs with self-attention mechanisms
To address these challenges, the authors propose three key techniques:
- Instead of using a traditional encoder, SpikeGPT aligns the sequence dimension of language with the temporal dimension of the SNN
- It employs autoregressive training instead of spike accumulation to compute the loss
- It uses stateful neurons to mitigate the adverse effects of spike binarization
SpikeGPT is the first LLM based on SNNs to achieve language and coding capabilities. It is also the largest trained SNN to date, with 216M parameters. The model integrates recurrence directly into the transformer block to make it compatible with SNNs, reducing computational complexity from quadratic to linear.
Their experiments show that SpikeGPT achieves competitive performance on mainstream NLP tasks while requiring significantly less energy than traditional LLMs based on ANNs.
2. Methods
2.1 Leaky Integrate-and-Fire Neuron
For their neuron model, the authors use the Leaky Integrate-and-Fire (LIF) model, which is defined as follows:
$$ \begin{aligned} U[t] &= H[t] + \beta (Y[t] - (H[t-1] - U_{\text{reset}})) \\ S[t] &= \Theta(U[t] - U_{\text{threshold}}) \\ H[t] &= U[t] \cdot (1 - S[t]) \end{aligned} $$Where:
- \(\beta\) is the decay factor
- \(U\) is the membrane potential
- \(S\) is the spiking tensor with binarized elements
- \(Y\) is the output of the previous RWKV block
- \(\Theta\) is the Heaviside step function
- \(H\) is the reset state after spike emission
To overcome the non-differentiability of the Heaviside operation \(\Theta\), the authors use the arctangent surrogate function during the backward pass, which provides a biased gradient estimator.
2.2 Model Architecture
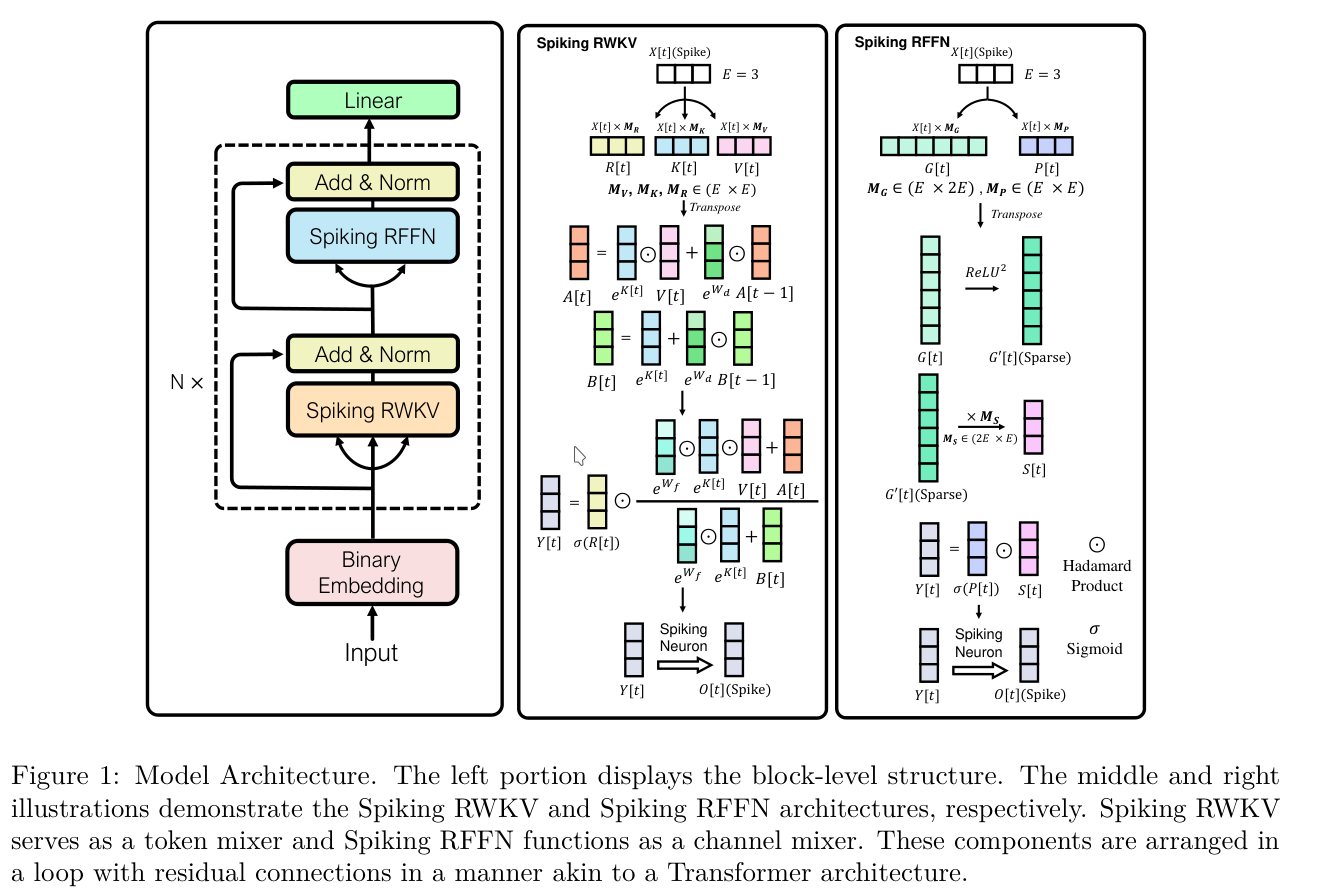
The model begins by using a binary embedding to transform the original word-embedded input \(I\) into a binarized representation \(X_0\). This input is then passed through a Spiking RWKV (SRWKV) block and a Spiking Receptance Feedforward Network (SRFNN). Together, they serve as a replacement for a traditional transformer block. Residual connections are also incorporated in each block.
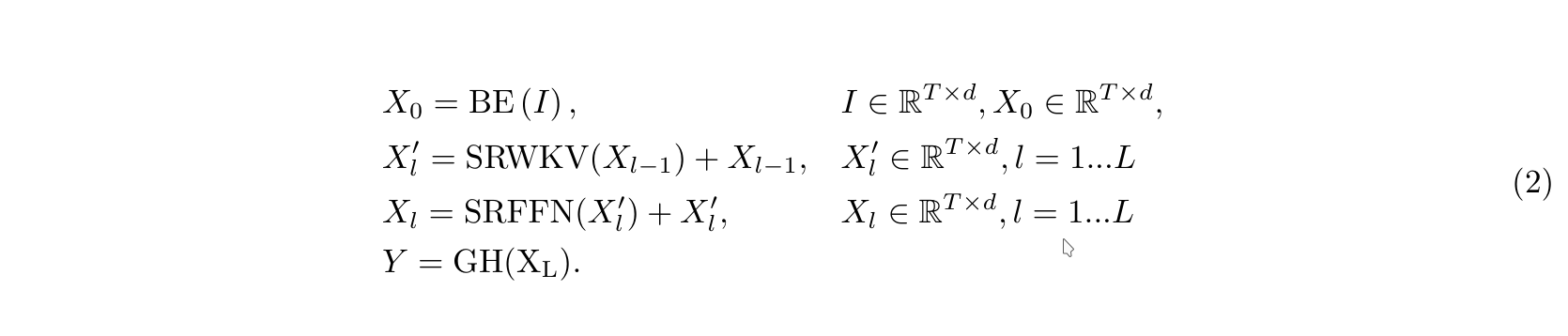
After each block, a token shift operation is applied.
2.3 Binary Embedding
Since LIF neurons operate with binary spikes, the authors introduce binary embedding, which converts continuous input signals into binary spike representations. The conversion is performed using the Heaviside step function. During backpropagation, this function is replaced by the arctangent surrogate, enabling gradient flow through non-differentiable operations.
2.4 Efficient Processing of Variable-Length Sequences Using Spiking RWKV
Recall: Self-Attention
In transformers, the self-attention mechanism is defined over the input sequence \(X\) as follows:
$$ f(x) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V, \quad Q = XM_Q, \quad K = XM_K, \quad V = XM_V $$This mechanism enables the model to dynamically determine which tokens to focus on during processing.
However, SNNs operate over temporal sequences, where spike firing depends on past activations. This temporal nature makes it impossible to access the full sequence at once, which self-attention requires. The optimal solution is to leverage the inherent sequence-processing nature of forward propagation in SNNs — specifically, by using a recurrent mechanism instead of self-attention.
Spiking RWKV
Spiking RWKV is inspired by the vanilla RWKV architecture. It incorporates both recurrence and block-level spiking. Unlike self-attention, Spiking RWKV does not require access to the entire sequence. Instead, it operates on unrolled input \(X[t]\), where \(t\) represents the time (or token) index.
It computes:
$$ R = X[t]M_R, \quad K = X[t]M_K, \quad V = X[t]M_V $$The output is then generated using the following equations:
$$ \begin{aligned} Y[t+1] &= \mathcal{SN} \left( \sigma(R[t]) \odot \frac{\exp(W_f) \odot \exp(K[t]) \odot V[t] + A[t]} {\exp(W_f) \odot \exp(K[t]) + B[t]} \right) \\[1em] A[t] &= \exp(K[t]) \odot \left( V[t] + \exp(W_d) \odot A[t-1] \right) \\[1em] B[t] &= \exp(K[t-1]) + \exp(W_d) \odot B[t-1] \end{aligned} $$Where:
- \(\mathcal{SN}\) refers to the spiking neuron layer
- \(\odot\) denotes element-wise multiplication
- \(W_f, W_d\) are learnable decay vectors:
- \(W_f\) controls the weighting of the current time-step
- \(W_d\) decays the influence of previous time-steps
- \(A[t], B[t]\) encapsulate historical information across steps
The major difference from self-attention is that Spiking RWKV avoids matrix-matrix multiplication. Instead, it uses learnable vectors \(W_f\) and \(W_d\) to recurrently blend the token dimension of the input.
Note: A major disadvantage of traditional RNNs compared to transformers is that RNNs depend on previous time steps, making them difficult to parallelize. For transformers, the entire input sequence can be processed in a single GPU computation step, while RNNs require sequential steps. It’s unclear whether this limitation still applies to RWKV. Further reading of the RWKV paper is needed to clarify this point.
2.5 Spiking Receptance Feed-Forward Networks (SRFFN)
After each SRWKV block, a Spiking Receptance Feed-Forward Network (SRFFN) is applied. This is a feed-forward layer augmented with a gating mechanism, along with normalization and token shifting operations. The SRFFN is defined as:
$$ Y'[t] = \text{SN} \left( \sigma(M_P X[t]) \odot M_S \left( \text{Activation}(M_G X[t]) \right) \right) $$Where:
- \(Y'[t]\) is the output of the SRFFN at time step \(t\)
- \(\sigma\) is the sigmoid gating function
- \(\text{Activation}(\cdot)\) is either ReLU or a spiking neuron (SN)
- \(M_P, M_G, M_S\) are learnable projection matrices
The SRFFN is a variant of the Gated Linear Unit (GLU). The gating mechanism regulates the flow of information into the model, helping control what passes through and what is suppressed.
2.6 Training & Inference
The training process is divided into two phases:
- Pretraining on a large-scale corpus
- Task-specific fine-tuning for downstream applications such as Natural Language Generation (NLG) and Natural Language Understanding (NLU)
For NLG tasks, SpikeGPT follows the typical decoder-only GPT architecture. The model generates an output distribution over tokens and is trained using the standard maximum likelihood objective.
For NLU tasks, such as sentiment classification, a classification head is added on top of the model.
2.7 Theoretical Energy Consumption Analysis

I’m curious: how much of the energy efficiency gain comes from using RWKV instead of standard attention, and how much comes from adopting Spiking Neural Networks (SNNs)?
3. Experiments
3.1 Experiment Setting
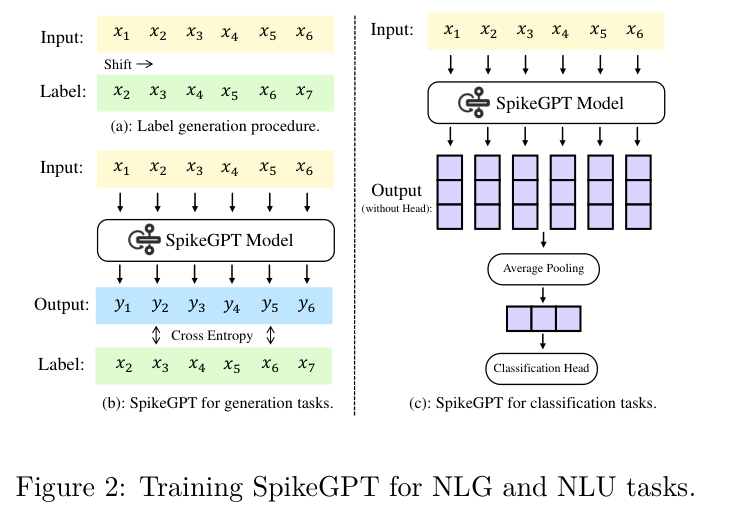
- A 46M parameter model was trained on Enwik8.
- A larger 216M parameter model was trained on OpenWebText2.
- Performance was evaluated using the Bits Per Character (BPC) metric.
- Dropout was set to 0.03 to prevent overfitting.
- Byte Pair Encoding (BPE) was used for tokenization.
- Training was conducted on 4× NVIDIA V100 GPUs.
Datasets used:
- Natural Language Generation (NLG): Enwik8, WikiText-2, WikiText-103
- Natural Language Understanding (NLU): MR, SST-5, SST-2, Subj
3.2 Results
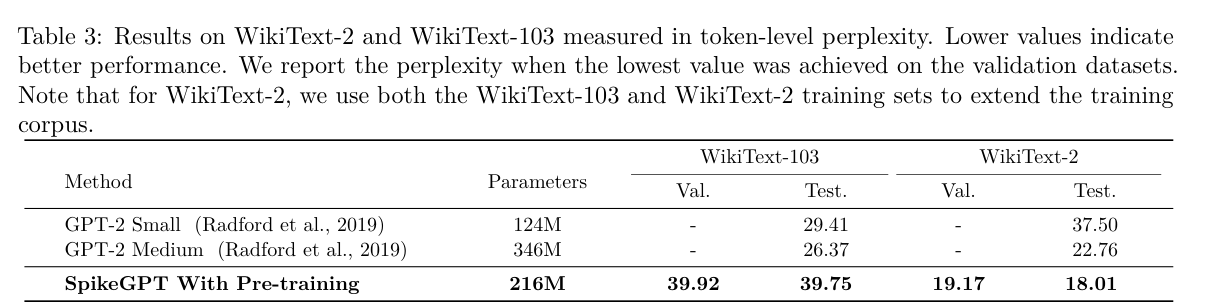
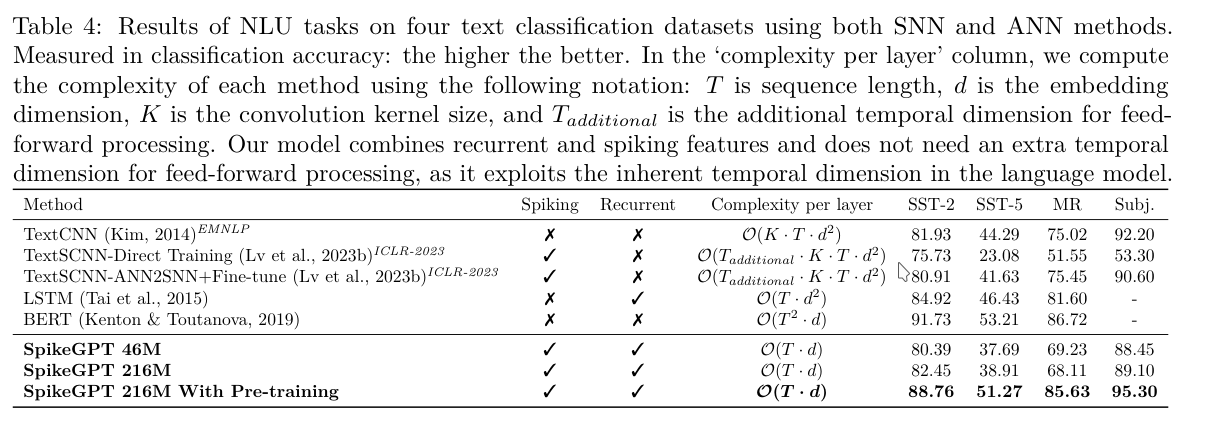
3.3 Scaling SpikeGPT
According to scaling laws, larger models trained on more data generally achieve better performance. To explore this for SpikeGPT, the authors evaluated models of three different sizes. Although they did not fully train all models due to computational constraints, their results show that loss consistently decreases as model size increases.
This indicates that SpikeGPT follows neural scaling laws, similar to traditional large language models.
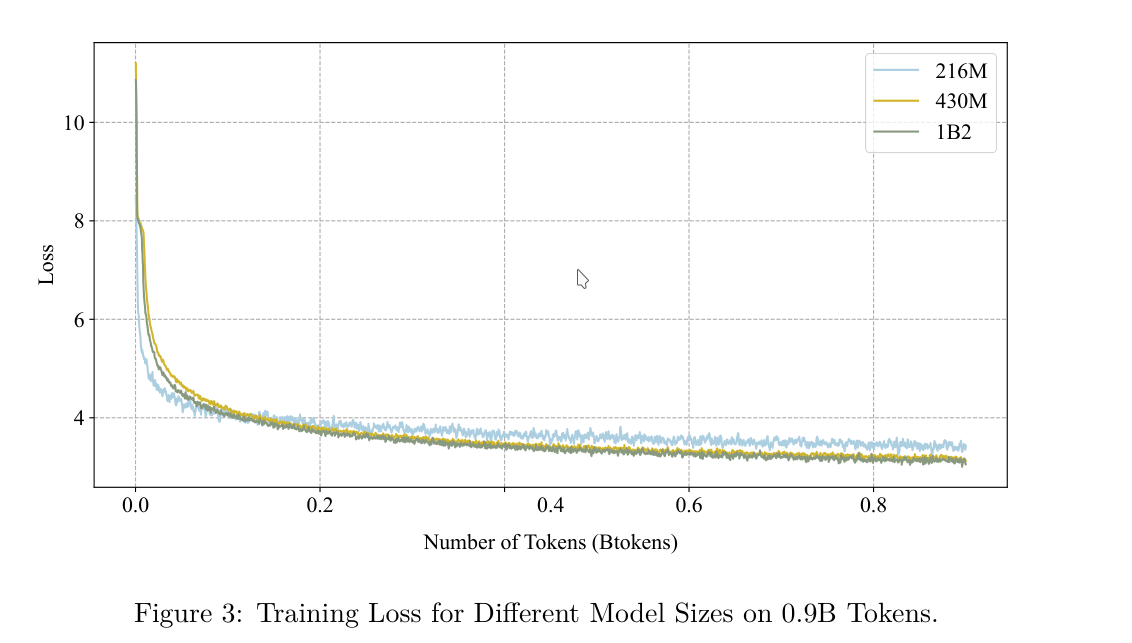
4. Conclusion
This paper presents the first working Large Language Model (LLM) based on Spiking Neural Networks (SNNs). The authors demonstrate that it’s possible to adapt autoregressive transformer-like architectures to the spiking paradigm using novel components like Spiking RWKV and Spiking Feed-Forward Networks, enabling language and code modeling capabilities with significantly improved theoretical energy efficiency.
My Thoughts
I’m skeptical about the practical value of this approach for two main reasons:
- Power Efficiency Uncertainty
The claimed 33× energy efficiency improvement is compelling, but it’s unclear how much of that gain comes from:
- The use of RWKV, which can also be implemented with traditional (non-spiking) neurons, and
- The use of neuromorphic hardware, which may speed up inference but could also be matched by specialized hardware for conventional neural networks. In short, it’s not clear if SNNs alone are responsible for the efficiency gains.
- Mismatch Between Spikes and Language One of the primary benefits of SNNs is their natural fit for spike-based signals—such as biological sensory data or event-driven streams. But written language is not natively spike-based. In this case, the model has to convert continuous language representations into binary spike signals, which may reduce the expressive power or efficiency. This makes me question whether SNNs are truly a good fit for token-based, symbolic data like natural language.
 reply via email
reply via email