Super-NaturalInstructions: Generalization via Declarative Instructions on 1600+ NLP Tasks
February 1, 2024 | 377 words | 2min read
Paper Title: Super-NaturalInstructions: Generalization via Declarative Instructions on 1600+ NLP Tasks
Link to Paper: https://arxiv.org/abs/2204.07705
Date: 16. April 2022
Paper Type: NLP, LLM, Instruction
Short Abstract:
In this paper, the authors investigate the generalization capabilities of NLP models to unseen tasks.
It’s one of the first papers that uses instructions finetuning.
1. Introduction
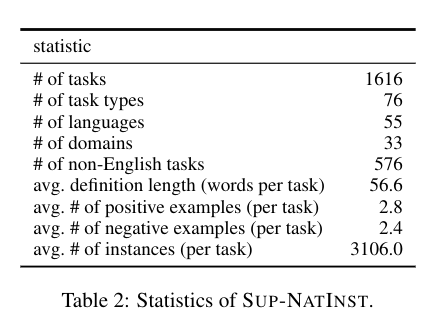
This paper constructs a meta-dataset called SUPER-NATURALINSTRUCTIONS, a large benchmark comprising 1616 NLP tasks along with their natural language instructions. Each task in the dataset is accompanied by an instruction that describes the task for the model.

Furthermore, they train their own transformer model called Tk-Instruct, which has 11 billion parameters and is evaluated on the SUPER-NATURALINSTRUCTIONS dataset.
2. SUPER-NATURALINSTRUCTIONS
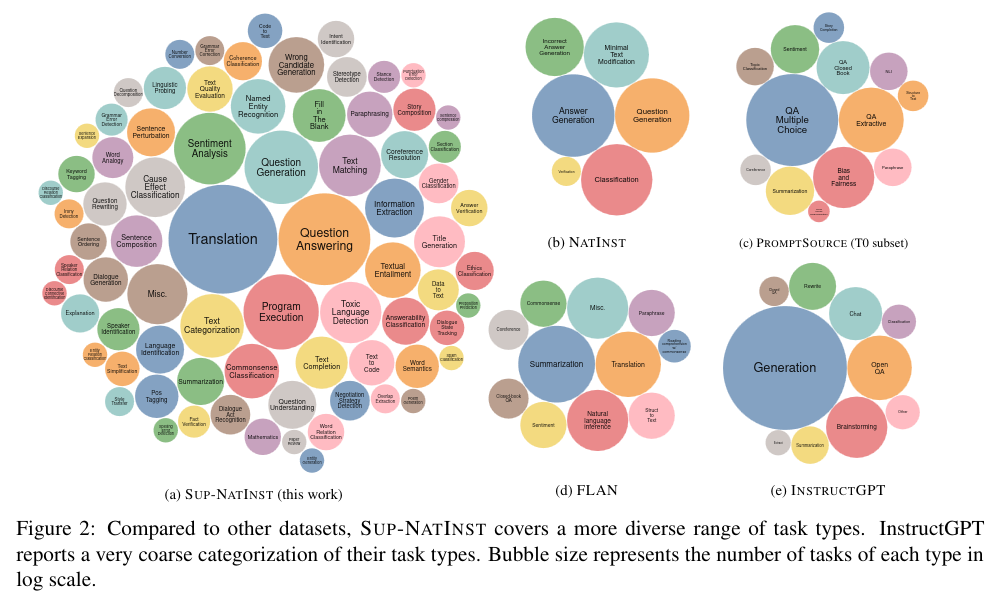
SUPER-NATURAL-INSTRUCTIONS is a meta-dataset consisting of various NLP tasks and plain language instructions that describe them.
All tasks in the dataset follow the same schema:
- Definition, which defines the task in natural language.
- Positive example, which are input examples along with their correct output.
- Negative example, which are input examples along with their incorrect output..
The model’s mission is, given the instruction for the task, to solve the instance of the task.
The benchmark was collected through a large community effort on GitHub, and quality control was conducted through automated tests and the review of GitHub pull requests.
3. T_k-INSTRUCT Model
Their model, Tk-INSTRUCT, is trained on SUPER-NATURAL-INSTRUCTIONS and based on the pre-trained T5 Models; each task is defined by a natural language instruction and some examples. The model is expected to solve these tasks based on the instruction and the examples. Basically they use the T5 Model as base and use their dataset to instruction fine-tune it.
4. Benchmarks and Results
The authors compare their Tk-Instruct model with other models such as InstructGPT.
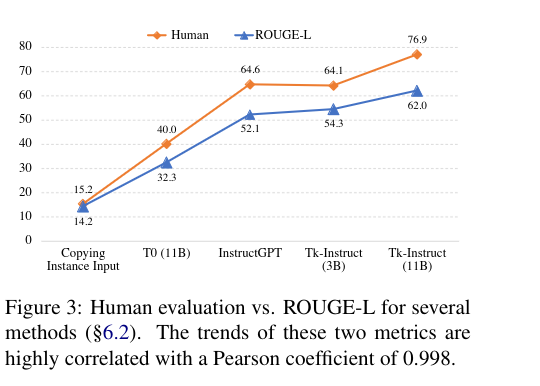
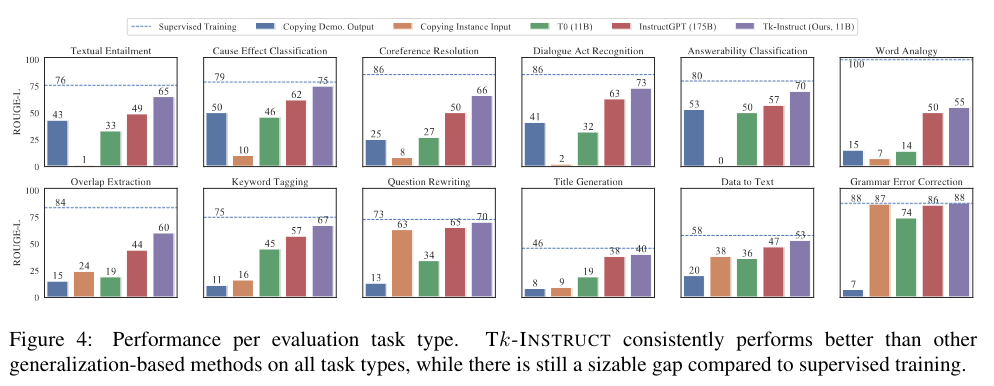
Overall, they find that instruction-tuning enables stronger generalization to unseen tasks. Instruction-tuned models perform better compared to their untuned LLM counterparts. Furthermore, they find that the more tasks a model observes, the better it becomes at generalization, while a large number of training instances help less.
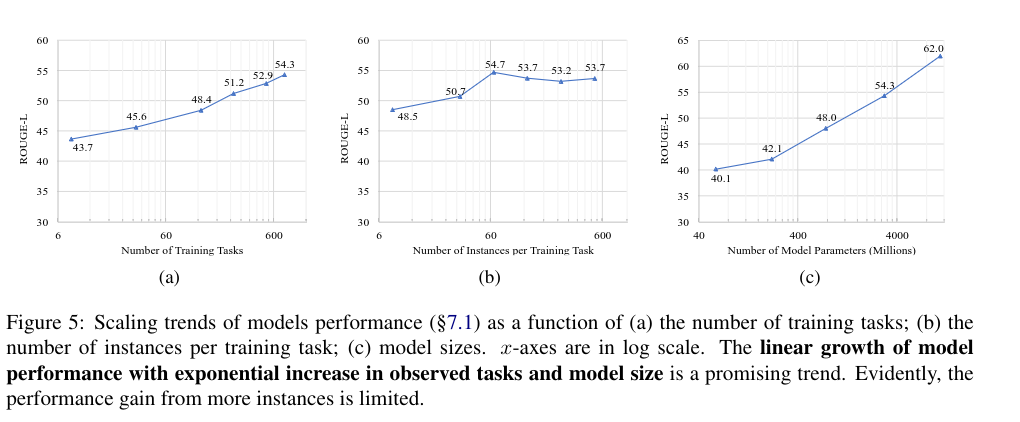
5. Conclusion
This paper, together with InstructGPT, demonstrates the power of instruction fine-tuning and how it can significantly increase the performance of LLM on NLP tasks. Furthermore, it provides a large dataset that allows the testing of models on a broad range of tasks.
 reply via email
reply via email