Toolformer: Language Models Can Teach Themselves to Use Tools
February 1, 2024 | 564 words | 3min read
Paper Title: Toolformer: Language Models Can Teach Themselves to Use Tools
Link to Paper: https://arxiv.org/abs/2302.04761
Date: 9. Feburary 2023
Paper Type: NLP, LLM
Short Abstract:
In this paper, the author demonstrates that Language Models (LLMs) can autonomously learn to use external tools through simple APIs. They introduce the Toolformer model, which is trained to showcase this unique ability.
1. Introduction
While LLMs excel in various Natural Language Processing (NLP) tasks, they face limitations, including the inability to access real-time information, the tendency to hallucinate facts, a lack of precise mathematical skills, and a lack of awareness of temporal progression.
One promising approach to address these limitations is to empower LLMs with the capability to use external tools such as search engines, calculators, or calendars.

Toolformer is a model that learns to use tools without requiring extensive human-annotated data. It retains its generality and autonomously decides when to leverage external tools.
To achieve this, the authors utilize LLMs with in-context learning to generate datasets from scratch based on a few human-made examples. They employ self-supervised loss to discard unhelpful data and fine-tune the LLM with the retained dataset.
Experiments indicate that Toolformer, based on GPT-J, exhibits stronger zero-shot performance than GPT-3.
2. Method
Each API that should be incorporated into the LLM need to be presentable as text sequences, this allows the integration of the API calls \(c=(a_c, i_c)\) with text, where \(a_c\) is the name of the PI, \(i_c\) the input and \(r\) the result. The encoding of API calls is illustrated in Figure 1.
e(c) = <API> a_c (i_c) </API>
e(c, r) = <API> a_c (i_c) \rightarrow r </API>
Given a dataset of plain text, the dataset is first converted into dataset with API calls, this is done in the following steps:
- Sample large amount of potential API calls
- Execute these potential API calls
- Filter out all API calls that are not helpful
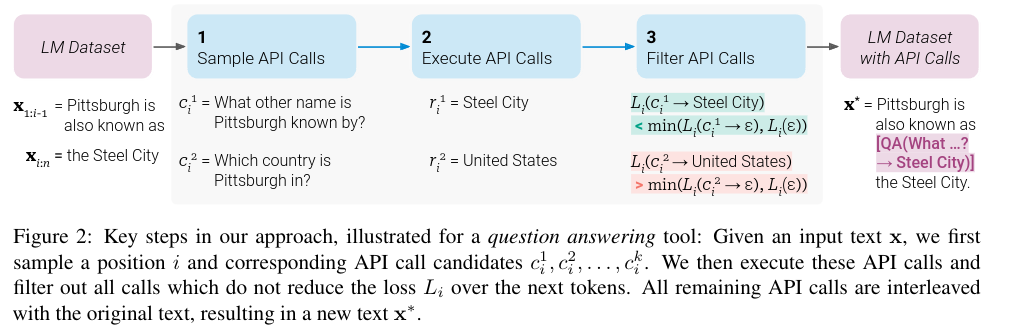
After filtering, the API calls are merged into the dataset, creating an augmented dataset for fine-tuning the LLM.
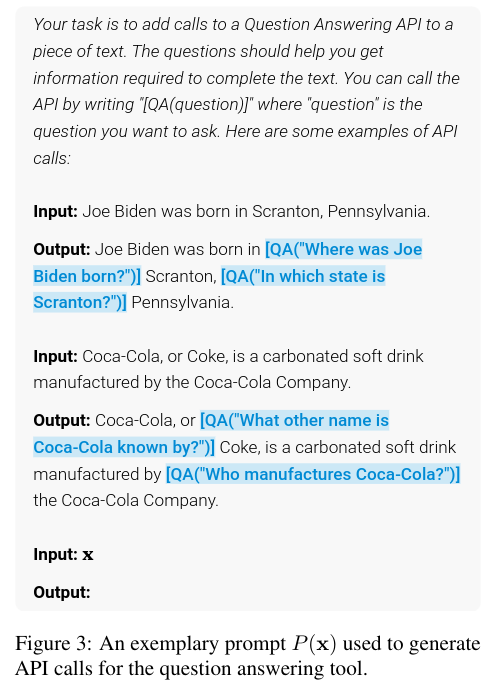
Sampling involves writing a prompt to encourage the LLM to annotate an example, selecting the top k candidate positions for the API calls by computing the probability of the <API> token.
Execution depends on the API call made, with the response required to be presentable as text.
To filter the API calls, the authors assess whether keeping the API call would decrease the loss when used; otherwise, it is discarded.
After sampling, the model is further fine-tuned on the augmented dataset, maintaining the original dataset apart from the inserted API calls.
In Inference, the LLM does decoding until it hits a “\(\rightarrow\)” token, at which point the API call is executed and inserted in its place.
3. Tools
In the paper they investigate the following tools:
- Expert Question Answering System
- Calculator
- Wikipedia search
- Machine Translation System
- Calendar

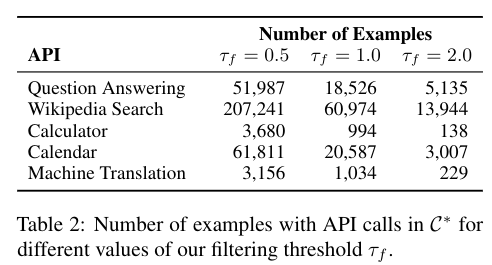
4. Experiments
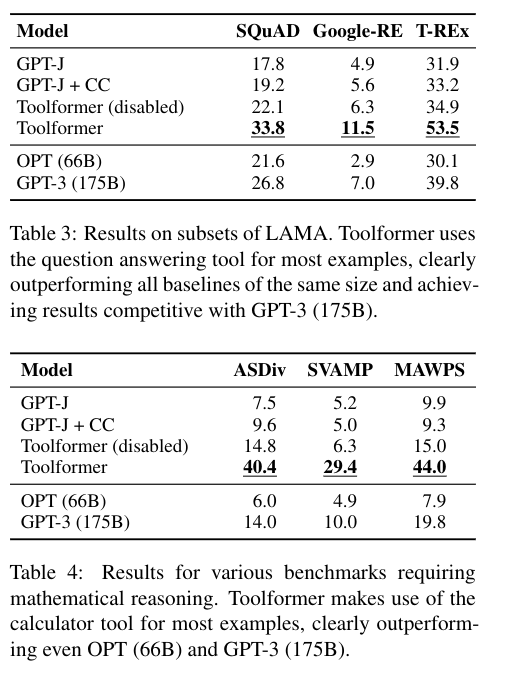
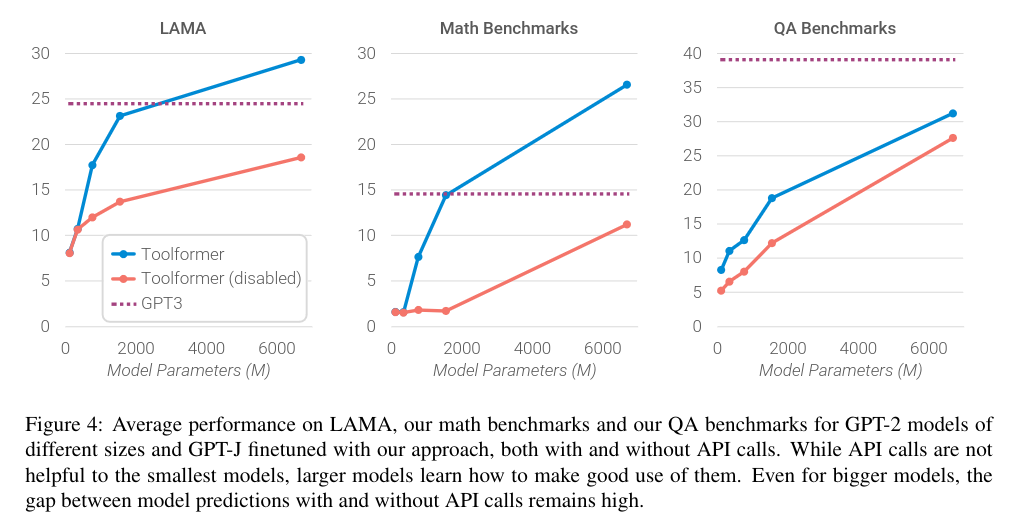
Enabling the model to make API calls more than doubles its performance in all tasks and surpasses larger models. However, Toolformer is not as effective as GPT-3, possibly due to its inability to interact seamlessly with API calls.
Training on the augmented dataset does not lead to an increase in perplexity compared to training on the un-augmented dataset.
5. Conclusion
It would be intriguing to further explore the limitations of Toolformer, such as:
- Ability of using API calls in a chain
- Allowing the LLM to interact with API calls, by iterating on them.
 reply via email
reply via email