Will we run out of data? An analysis of the limits of scaling datasets in Machine Learning
January 31, 2024 | 328 words | 2min read
Paper Title: Will we run out of data? An analysis of the limits of scaling datasets in Machine Learning
Link to Paper: https://arxiv.org/abs/2211.04325
Date: 26. Oct 2022
Paper Type: NLP, Vision, Datasets
Short Abstract:
In this paper, the authors approximate the total amount of existing data and, based on that, analyze how long it will take before we run out of data.
1. Introduction
In ML models, one important aspect of model performance is the quality and the amount of training data. As such, it’s important to understand how much data exists and if we are going to run out of it.
2. Method
To analyze the growth of training dataset sizes, they use historical data in combination with considering scaling laws of the optimal dataset size. They assume that the amount of internet users worldwide can be predicted by an S-curve over time. For simplicity’s sake, they assume that the average production of data by users is constant over time and use a model to predict the accumulation rate of user-produced content. For high-quality data, they predict the accumulation rate based on the most common resources, e.g., Wikipedia, books, etc.
3. Analysis
Their findings show that language datasets double in size after 15.8 months, and vision datasets after 41.5 months. Furthermore, they approximate the aggregated total stock of low-quality language data to be between 6.9e13 and 7.1e16 words. For high-quality language data, they approximate the stock of data to be 9e12 words. The aggregated model shows there are between 8.11e12 and 2.3e13 images on the internet today.
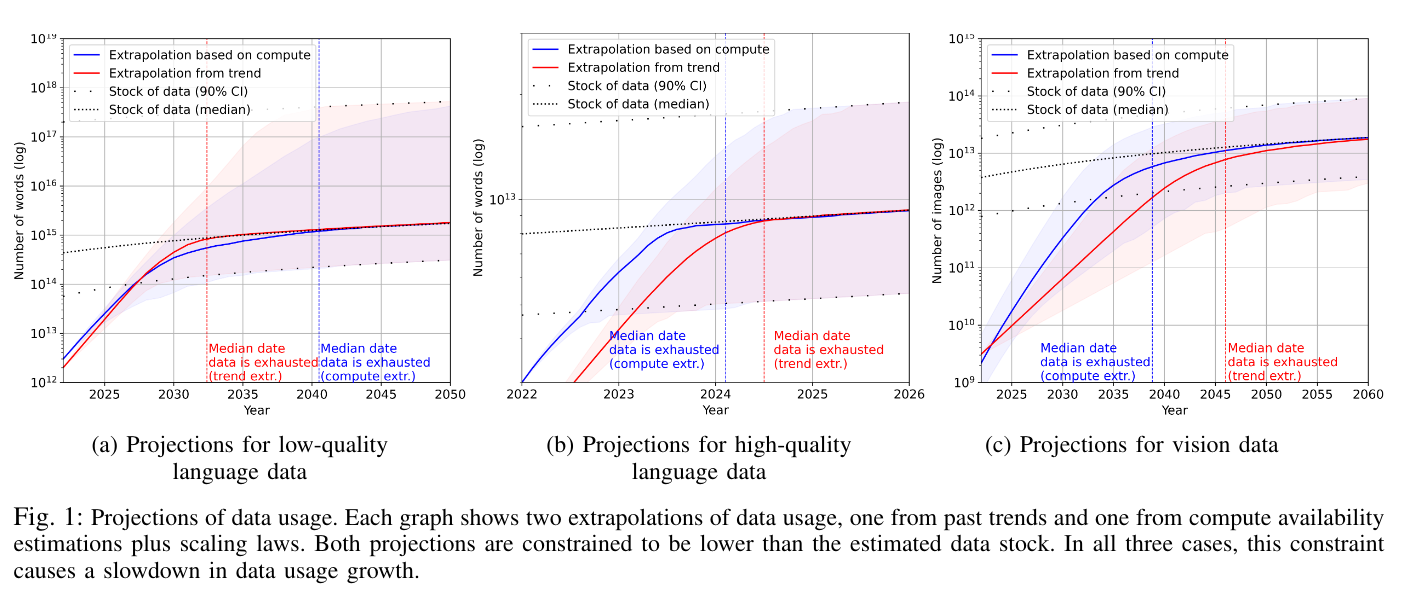
They compute that low-quality language data will be exhausted between 2030 to 2060, and high-quality data will most likely be exhausted before 2027 if current trends continue.
4. Conclusion
If the models of the authors are correct for predcition the date of exhaustion for data, we will still have some time for lower quality, but for higher quality not. This should show clearly the need for data efficient trainings methods.
 reply via email
reply via email